
애플에서 공개한, 모델을 SSD에 탑재하고 효율적으로 swap하여 부족한 DRAM을 커버할 수 있는 신박한 방법을 다룬 논문이다.
요약
LLM의 크기가 증가함에 따라, 모델을 load하기 위해서 너무 많은 DRAM이 필요하게 되는것이 문제.
해당 논문에서는 모델의 일부를 DRAM이 아닌 Flash memory로 불러와, DRAM보다 더 큰 사이즈의 LLM모델을 실행하고, 이런 과정에서 발생하는 DRAM과 Flash memory 간 swap을 어떻게 효율적으로 수행 할 수 있었는지를 기술한다.
1. 개요
GPT3, OPT, PaLM과 같은 LLM 모델은 자연어 처리에 있어서 아주 좋은 퍼포먼스를 보여줬으나, 모델을 실행시키기 위한 메모리 요구사항이 너무 큰것이 문제였다 (7B 모델 실행을 위해서는 14GB 메모리 이상 필요)
이러한 제한사항을 해결하기 위해, 해당 논문에서는 모델의 파라미터를 SSD에 넣는 방법을 제안한다.
SSD에 모델을 적재시켜놓고, 필요한 파라미터만 DRAM에 전송해서 사용하는 방법이 DRAM에 모델 전체를 적재하는 것에 비해 메모리 제한사항을 해결할 수 있음
LLM의 매개변수가 희소성(sparsity)를 가진다는 점을 이용하여, 추론 과정에서 Flash memory로부터 필요한 매개변수만을 선택적으로 불러온다. 매개변수가 실제로 입력이 비어있지않은(non-zero input) 경우나 출력이 비어있지 않을것으로 예상되는(non-zero output) 경우만 불러온다.
본 논문에서는 데이터 전송을 최소화하고 데이터를 크고 연속적인 덩어리로 읽어들이기 위해 크게 두가지 방법이 제시된다.
1. Windowing
최근 계산된 토큰의 activations를 재사용하여, 과거 몇개의 토큰에 대한 매개변수를 메모리에 로드한다. sliding window 방식을 사용하여 Flash memory - DRAM 간 입출력 요청 수를 줄일 수 있다
2. Row-column bundling
up-projection과 down-projection 층의 행과 열을 연결하여 저장하여, Flash memory에서 더 큰 연속된 덩어리를 읽을 수 있어 random access보다 더 빠르게 데이터 읽기가 가능하다
FFN 희소성을 예측하고 zero-output 파라미터를 불러오는것을 피함으로써, 추론쿼리 당 FFN layer의 2%만 Flash memory에서 가져오면 된다.
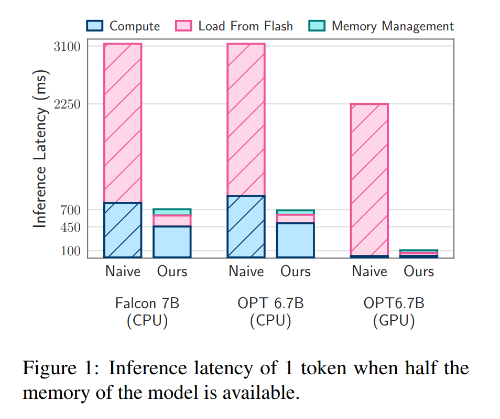
이런 전략들을 사용함으로써, 기기의 DRAM보다 2배 큰 모델을 구동할 수 있게 되었고, cpu에서는 4-5배, gpu에서는 20-25배 빠르게 추론할 수 있다.
2. 플래시 메모리와 LLM 추론

CPU-GPU 전송속도는 10GB/s, Flash memory - DRAM 간 전송속도는 1GB/s
현대 NAND 플래시 메모리의 성능이 향상되었으나, DRAM에는 한참 미치지 못한다
DRAM이 충분한 상황에서도, 모델 전체를 로드하는 초기 과정에서 느릴 수 있는데, 필요한 파라미터만을 선택적으로 로드함으로써 시간과 비용을 감소시킬 수 있다.
플래시 메모리는 연속적인 읽기에서 최적의 성능을 보이는데, 이상적인 연속적 읽기 벤치마크와 다르게 실제적으로 사용되는 랜덤 읽기는 지연시간이 증가하고 성능이 감소된다.

위 그래프에서, 더 큰 chunk를 읽었을 때, 데이터 대비 요청시간이 감소하여 효율적인 읽기를 수행할 수 있다.
또한, 필요한것보다 더 많이 읽어들인 후, 불필요한 부분을 버리는것이 오히려 더 빠를 수 있다는 흥미로운 결과가 나타남
또, 병렬읽기를 여러 스레드에 걸쳐 사용하여, 데이터를 더 빠르게 읽어들일 수 있었다. (그래프의 Threads 부분)
3. Load from flash
모델 사이즈가 메모리보다 큰 경우, 모델의 일부를 flash memory에 저장해야 되는것은 필연적이다.
이런 상황에서 플래시 메모리에서 로드하는 전략을 평가하기 위한 지표는 지연시간(latency)로, 플래시에서의 로딩 I/O 비용, 새로 로드된 데이터로 메모리를 관리하는 오버헤드, 추론연산에 대한 계산비용으로 구성된다.
3.1 데이터 전송 절약
LLM 모델이 FFN 구조에서 많은 희소성(sparsity)를 가지는 것에 기인하여, 추론과정동안 비희소(non-sparse) 데이터만을 Flash memory에서 DRAM으로 반복적으로 전송하여 처리하는 것으로 데이터 전송을 절약 할 수 있다.
선택적 지속성, ReLU 희소성 예측, 슬라이딩 윈도우 방법과 같은 접근 방식을 사용하여 데이터 전송을 최소화하고 이를 효율적으로 수행한다.

위의 a 그래프에서, window size가 증가할수록 더 많은 데이터를 불러와야 하므로 aggregated usage는 window size와 비례하여 증가한다.
그러나 이전의 토큰을 재활용할 경우, 새로 필요한 데이터의 갯수는 window size가 증가하면 오히려 줄어들게 된다. 이러한 근거로 sliding window를 활용할 수 있다.
그림 b는 sliding window를 활용할 때 초기 window와 그 다음 상태(window가 한번 slide된 상태)를 나타낸 것이다. 각각의 window 아래에 있는 neuron을 보면, 다음상태로 넘어갔을때, 기존의 토큰들을 재활용 함으로써 연산 횟수를 감소시키고, 일부 뉴런만 새로 불러오거나 삭제시키면 되는것을 보여주고 있다.
3.2 증가된 chunk size로 전송 개선
플래시 메모리에서 더 많은 데이터를 한번에(chunk) 읽어들이기 위해 아래와 같은 전략을 사용한다
-행과 열의 묶음
상향 프로젝션의 i열과 하향 프로젝션의 i행의 사용은 i번째 중간 뉴런 활성화와 일치한다는 점을 이용하여 상응하는 행과 열을 미리 저장하여, 데이터를 더 큰 덩어리로 읽어들일 수 있다.
-공동 활성화 기반 묶음
특정 뉴런이 활성화 될때, 그 뉴런과 가장 자주 같이 활성화 되는 뉴런(closest friend)이 있다. 이러한 근거를 바탕으로, 공동 활성화 뉴런들을 묶음으로 저장하여 공동 활성화 되는 뉴런을 미리 로드하는 전략을 수립했다.
그러나, 이는 활동이 많은 뉴런들을 여러번 로드하는 결과를 초래했고, 원래 의도와는 다르게 작동했다.
그냥 자주 활성화되는 뉴런이 모든 뉴런들의 closest friend가 된것이다.

3.3 DRAM에서 데이터 관리 최적화
디램이 플래시메모리보다 충분히 빠르지만, 여전히 무시하지 못할 만큼의 cost를 소모한다(최적화를 해야한다는 뜻)
새로운 뉴런을 가져왔을 때, 매트릭스를 재할당하고 추가하는 것은 기존 뉴런들을 다시 써야하므로 overhead를 발생시킬 수 있다.
이런 문제를 해결하기 위해, 아래와 같은 방법을 사용한다

남아있는 모델을 삭제되어야 할 자리에 덮어 쓴 뒤, 범위를 지정한 후 그 뒤에 새로운 데이터를 덮어씌움으로써, 이미 DRAM 내에 남아 있는 데이터를 재활용한다. 이를 통해 전체 데이터를 다시 복사해야 할 필요가 없어진다.
https://arxiv.org/abs/2312.11514
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their intensive computational and memory requirements present challenges, especially for devices with limited DRAM
arxiv.org
'AI' 카테고리의 다른 글
| 모개숲 딥러닝 스터디 - 3. ResNet : Deep Residual Learning for Image Recognition (1) | 2024.03.24 |
|---|---|
| 모개숲 딥러닝 스터디 - 2. You Only Look Once Unified, Real-Time Object Detection (1) | 2024.03.17 |
| 논문 리뷰 - The Era of 1-bit LLMs:All Large Language Models are in 1.58 Bits (0) | 2024.03.14 |
| 모개숲 딥러닝 스터디 - 1. VAE & GAN & Diffusion model (1) | 2024.03.10 |
| 논문 리뷰 - OpenVoice: Versatile Instant Voice Cloning (0) | 2024.01.19 |