

SKT FLY AI 4기 프로젝트 RECLOS에 사용한 논문 리뷰

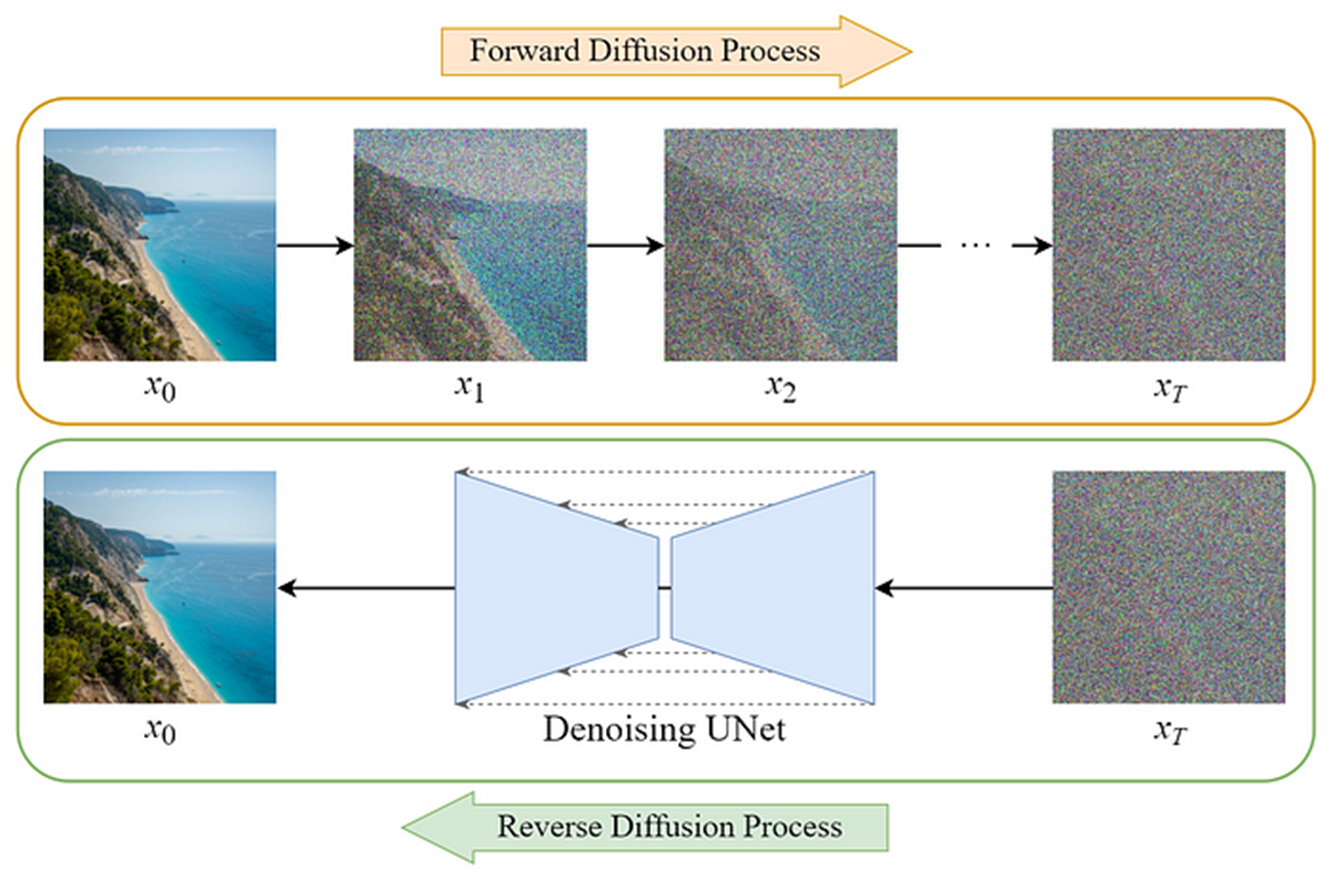
Diffusion Model


노이즈를 추가하는 forward process와 노이즈를 제거하는 reverse process로 구성
노이즈를 추가할 때는 랜덤 정규분포를 적용
추가된 노이즈를 점진적으로 제거해서 원래 이미지를 추정하는 프로세스
Reverse process도 정규 분포를 통해 정의할 수 있다고 가정
평균과 분산을 학습하여 안정적인 생성이 가능
UNet
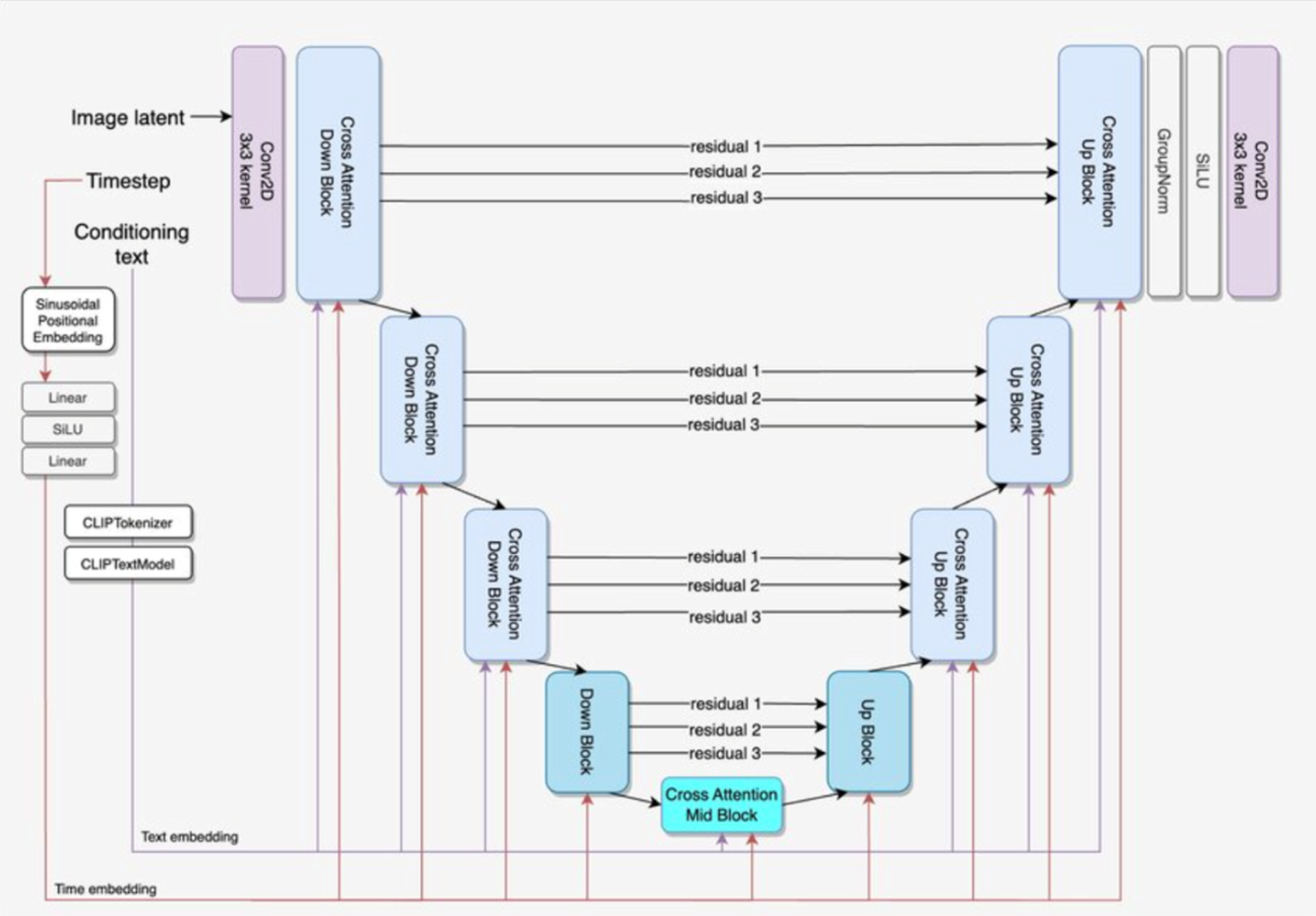
Image Segmentation을 위한 구조, 같은 size의 residual을 참조하여 정밀한 segmentation이 가능
이 구조를 Diffusion Model에도 활용
LaDI-VTON (Latent Diffusion Textual-Inversion Enhanced Virtual Try-On)

모델 사진 A와 옷 사진 B를 인풋으로 넣으면 B를 입은 모델 A의 사진이 출력되는 모델
Latent Diffusion Model을 최초로 가상 피팅에 적용
핵심 기술 → 모델의 물리적 특성, 포즈, (옷과 모델의)정체성을 유지하는 새로운 이미지를 생성하는 것

PTE(pseudo-word token embeddings) - 옷 이미지

옷의 특징(질감, 핏 등)을 잘 나타내는 문장을 labeling
해당 문장을 사전 훈련된 lookup table로 임베딩해서 벡터 공간 W에 위치시킨다.
lookup table → 특정 단어와 맵핑되는 정수를 인덱스로 가지고 있는 테이블
CLIP 임베딩의 핵심 과정인 텍스트-이미지 쌍을 학습하는 방법을 이용해서 옷을 가장 잘 설명하는 글을 예측하도록 훈련
PTE 과정을 통해 원본 의류의 디테일과 질감을 최대한 보존할 수 있음
CLIP (Contrastive Langauge-Image Pre-training)
자연어와 이미지 쌍으로 Image Classification 모델을 훈련시킬 수 있는 방법
별도의 labeling이 필요 없는 방식이기 때문에 인터넷 상의 방대한 자료들을 raw text 자체로 학습시킬 수 있다.

N개의 대각원소들 각각의 코사인 유사도를 최대화하고, N^2 - N개의 나머지 원소들의 코사인 유사도는 최소가 되도록 학습시킨다.
손실 함수는 cross-entropy loss 사용
입력 포즈에 맞게 의상 변형

원본 사진에서 추출한 사용자의 포즈맵, 마스킹(m,p,z)을 이용해서 변형된 옷 사진 C_W 생성
Toward Characteristic-Preserving Image-based Virtual Try-On Network 논문을 통해 구현
Diffusion-Network 훈련 (Fine Tuning)
디퓨전의 네트워크를 파인튜닝하는 과정 (사전 훈련된 디퓨전 가중치 사용)
포즈맵(p)과 변형된 옷(C_W), 마스킹된 영역(I_M)을 모두 인풋으로 넣기 위해 모델의 입력 차원 확장
포즈맵과 변형된 옷을 같이 사용하는 이유 → 변형된 옷(C_W)을 생성하는 과정에서 포즈에 대한 손실이 일어났을 수도 있기 때문
EMASC(Enhanced Mask-Aware Skip Connection) 모듈
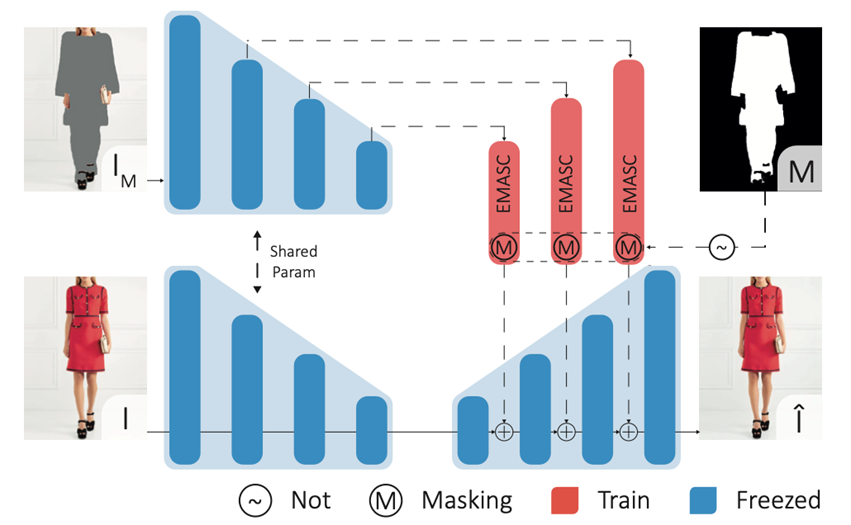
디퓨전 과정에서 이미지를 압축할 때 모델의 특성(얼굴, 손, 발 등)을 보존하기 위해 추가한 모듈
Skip Connection을 통해 Unet을 거치지 않고 인코더에서 디코더로 전달.
EMASC 출력을 처리하여 마스킹된 영역(M)이 디코더로 전달되지 않게 함.
EMASC 모듈은 두 개의 컨볼루션 레이어로 구성되며, 첫 번째 레이어는 SiLU 비선형 활성화 함수를 사용
SiLU(Sigmoid Linear Unit) 활성화 함수


ReLU보다 비선형성이 높은 것이 특징으로, 특정 상황에서는 ReLU보다 더 나은 성능을 보이기도 함
Results

Code
추론서버 구축을 위한 최적화 진행, 코드 함수화 후 Flask로 각 함수를 호출하였음