모개숲 딥러닝 스터디 - 2. You Only Look Once Unified, Real-Time Object Detection
1. YOLO의 등장 배경
이미지 인식의 종류
- Statistical Template Approach (Pedestrian detection)
이미지의 통계적 속성을 추출하여 사용
- Parts-based Model (Deformable part model)
객체를 개별부분의 집합으로 보고, 이들간의 상대적인 위치와 관계를 학습
- Two-stage Model (R-CNN, Fast/Faster R-CNN)
객체 검출 - 분류 두 단계로 처리. 높은 정확도, 높은 계산비용
- Single-stage Model (YOLO)
객체 검출 - 분류를 한 단계에서 처리

2. YOLO의 특징
2.1 Two-stage (R-CNN)
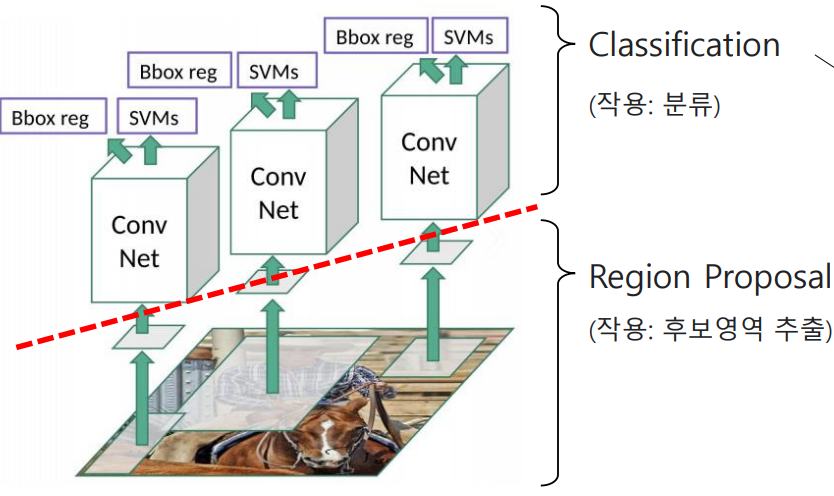
Region proposal과 classification이 순차적으로 진행됨
두개의 stage가 명확하게 분리되어 있으며, region proposal이 끝나야 classification이 실행됨
2.2 Single-stage (YOLO v1)
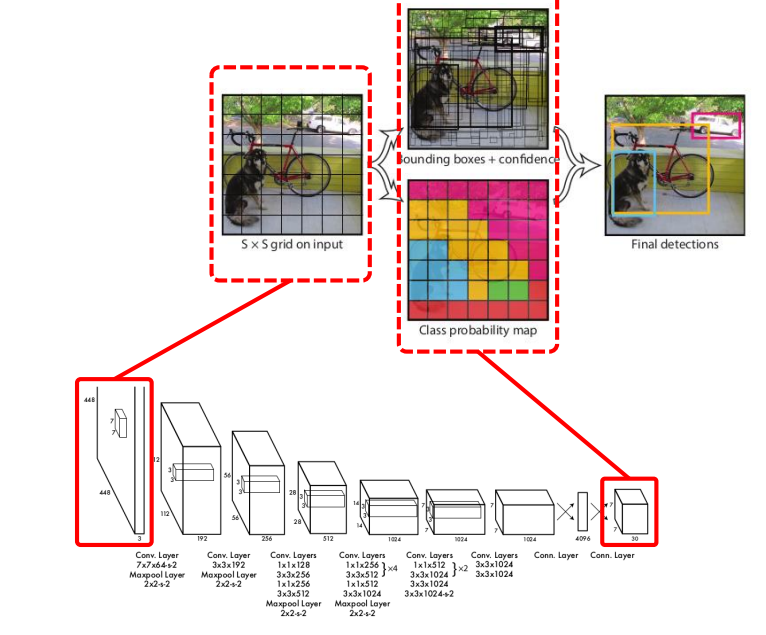
Bounding box, confidence, class probability가 한꺼번에 계산 됨
Bbox가 계산된 후에 probability가 계산되는 것이 아니며, localization과 classification 이 한꺼번에 진행
3. YOLO의 구조
3.1 YOLO v1의 핵심 아이디어:
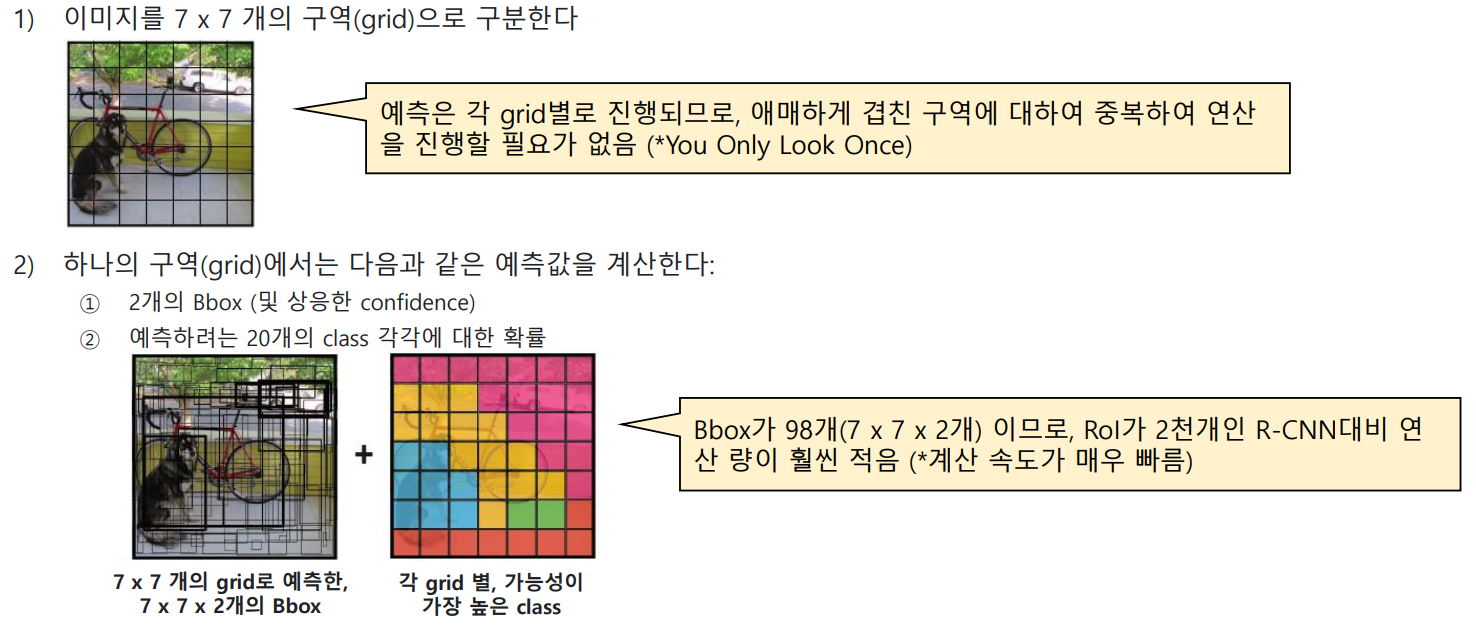
3.2 YOLO v1의 아키텍처
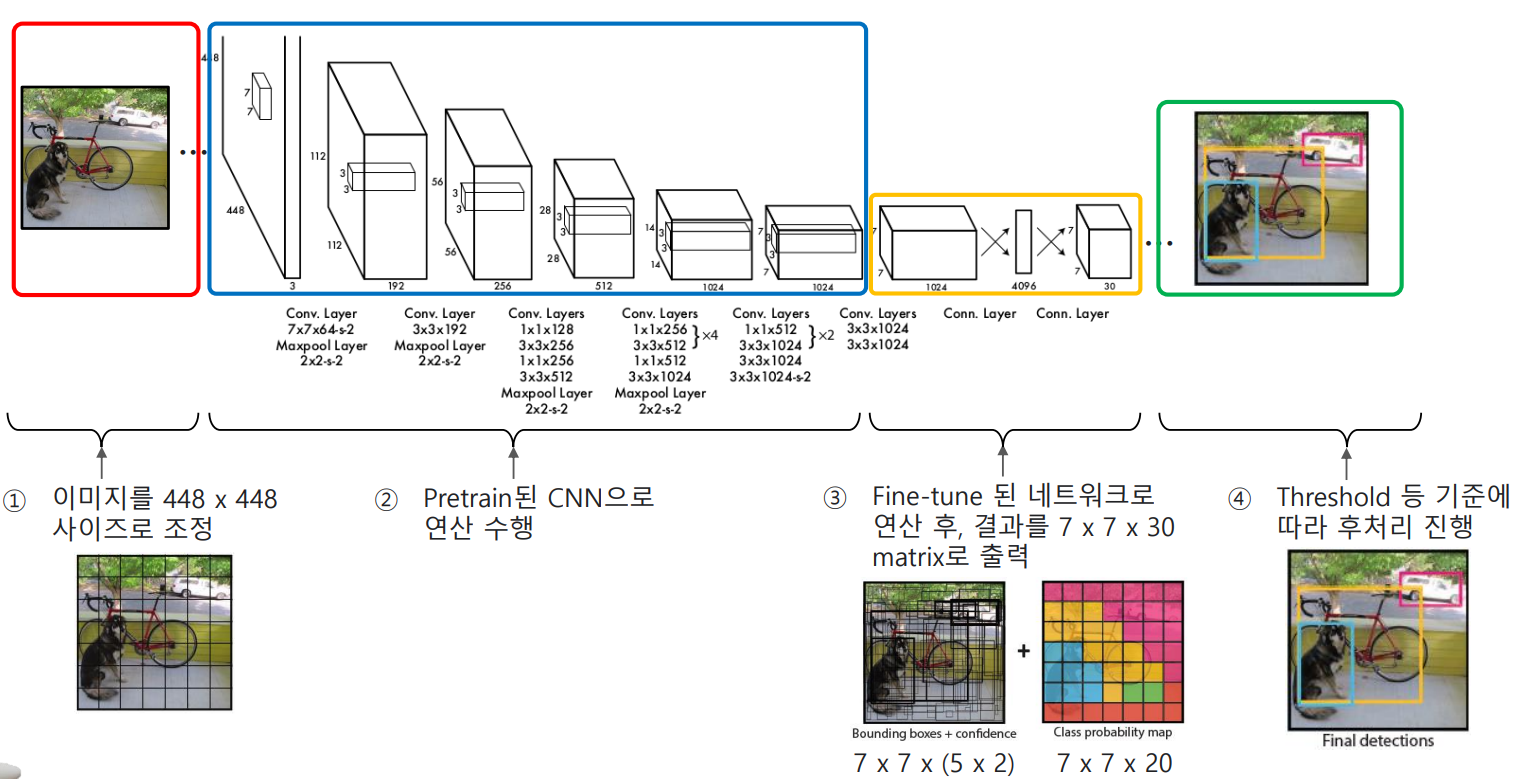
3.3 Training 과정
Pretrain : “ImageNet 1000-class competition dataset”을 사용하여 20개의 Conv layer에 대하여 pretrain 진행
Fine-tune : (성능 향상을 위하여) Pretrain이 끝난 후, Pretrain 된 20개의 Conv layer는 fix 시키고, 뒤에 4개의 Conv layer와 2개의 FC layer를 추가하여 fine-tuning 진행
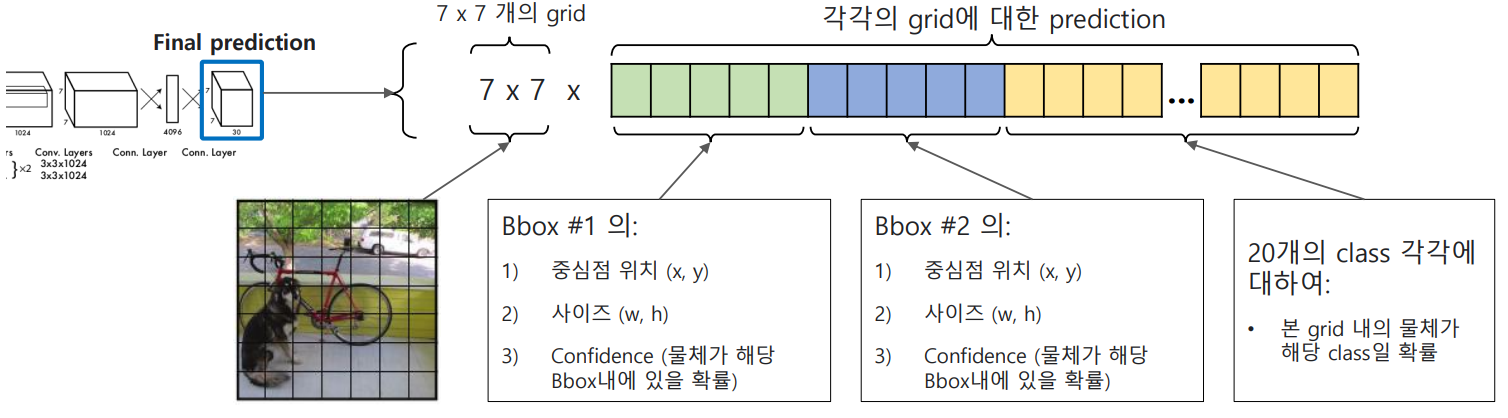
3.4 Output
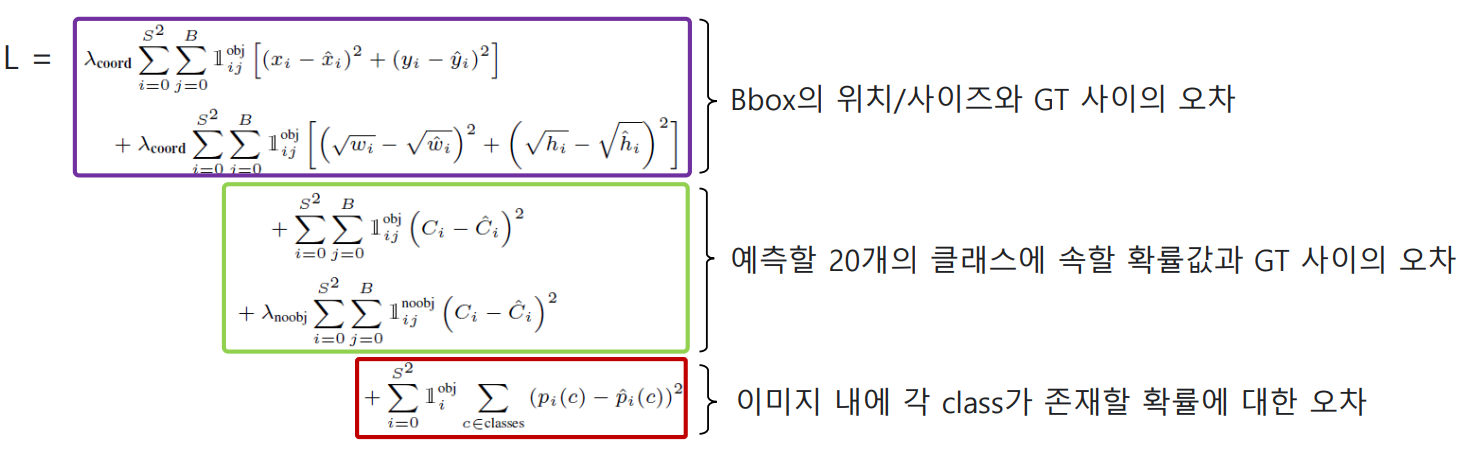
3.5 Loss Funciton
4. Summary
• YOLO는 Single-stage detection model 임
• YOLO는 실행속도가 매우 빠름 (RealTime detection 가능)
• YOLO의 정확도는 SOTA가 아니지만 준수한 편이며,
실행속도를 고려하면 종합적인 performance가 매우 뛰어남