AI
모개숲 딥러닝 스터디 - 7. Attention Is All You Need
META_BS
2024. 4. 18. 21:31

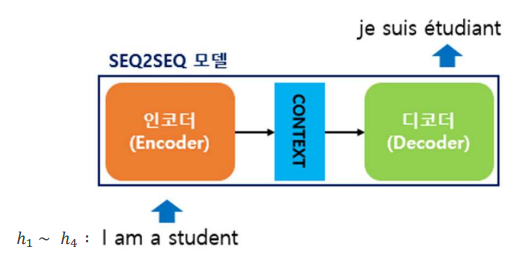
seq2seq
Input과 output을 sequence대로 계산
Input을 하나의 벡터로 압축하기에 그 과정에서 손실이 발생함
문장의 경우 중요한 문맥 정보의 상실
이를 해결하고자 인수분해트릭, 조건부계산을 사용하여 효율이 향상되는 듯 하였으나 문장이 길어질수록 학습이 느려지는 근본적인 문제를 해결하지 못함
Attention


위 링크가 설명을 엄청 잘해놔서 참고하시면 좋습니다
Input Embedding
각 단어는 벡터로 표현됨
사전에 준비(학습)된 단어 임베딩을 사용
Positional Encoding
문장에서 단어의 위치 또한 중요하므로, 다수의 sin, cos 함수를 결합한 Positional Encoding을 추가
Encoder

Self-Attention


Add, Norm

Decoder / Masked Self-Attention

Self-Attention의 장점
1. 각 layer의 시간복잡도 감소
2. 계산의 많은 부분을 병렬처리 가능 (행렬 곱)
3. Long-term dependency에 대해 효율적인 처리 가능

After Attention
Attention model의 차기작 - 계산 및 메모리 부담을 줄이는 방향으로 연구되고 있음
- Sparse Attention:
더 적은 input을 계산
- Long range Attention:
Input이 매우 길 경우 분할, 더 긴 input을 처리
- Efficient Attention:
효율적으로 어텐션 계산
- Structured Attention:
Input을 이웃 단어간 관계, 문장 전체의 단어 중 핵심 단어를 찾음