모개숲 딥러닝 스터디 - 10. The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits

Large Language Model(LLM)
다양한 해결방법의 등장으로 위 전제가 어느정도 해결된 상태 (Scale is all you need)

Model
- 인공지능 모델은 “함수”이다.
- Input x -> output y
- Trainable parameters : W, b
z11 = X1 * W11 + X2 * W21 + b1
a11 = activation(z11)
역전파를 이용하여,
입력에 대한 함수의 출력과 실제 정답 간
오차를 줄이도록 W와 b를 바꾸는 과정

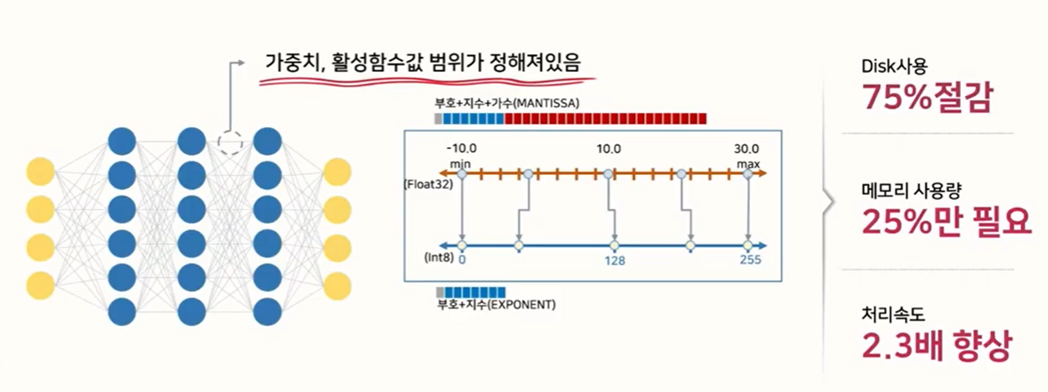
Quantization
모델 사이즈 축소
모델 연산량 감소
효율적인 하드웨어 사용

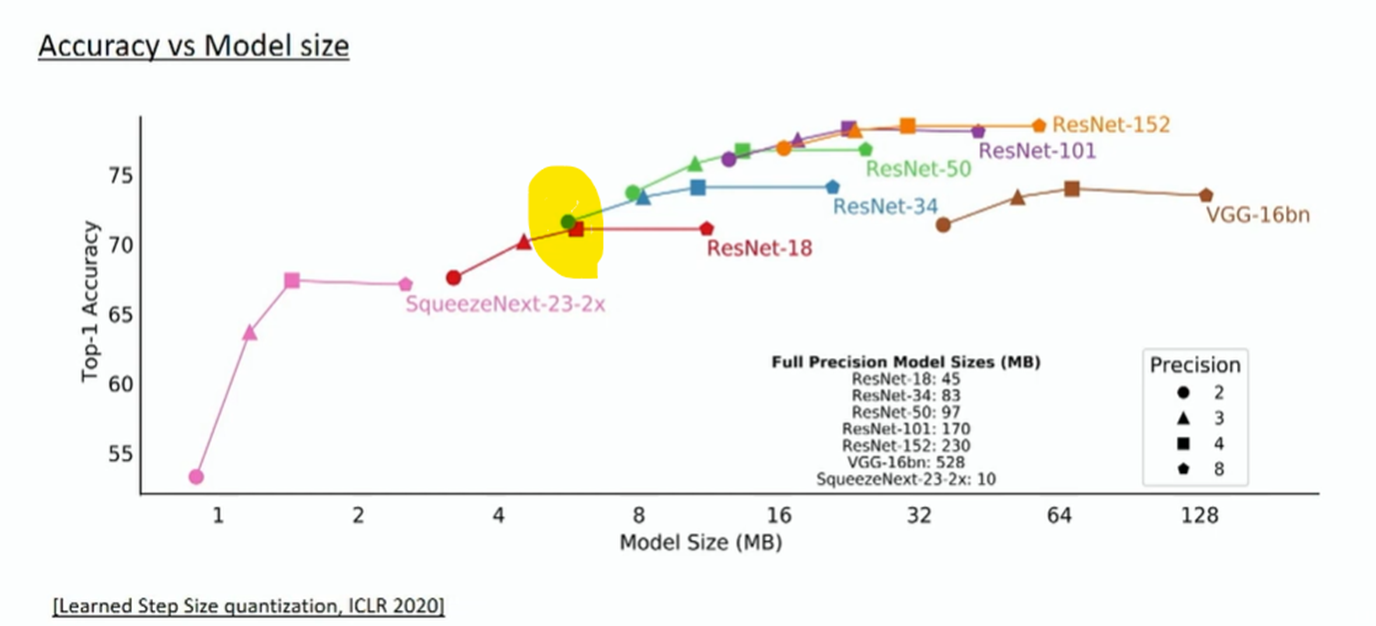
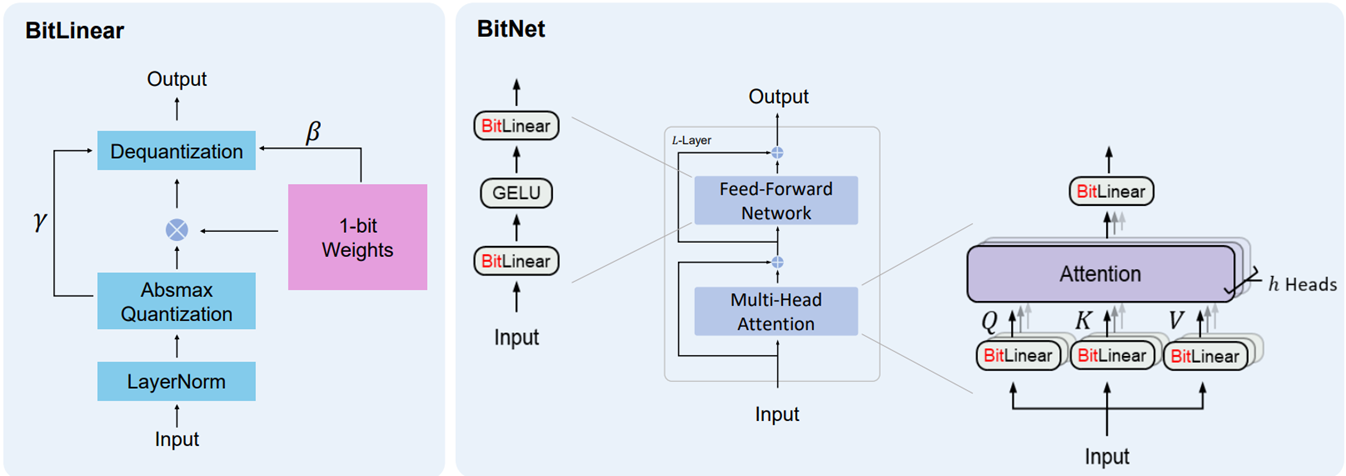
1.58 Bit LLM

2비트와 3비트 사이 : log_2(3) = 1.5849…
b1.58은 기존의 1비트 BitNet의 이점을 유지하면서,
모델 가중치에 0이 포함되어 기능 필터링을 가능하게 하여 모델링 능력 향상 -> 성능을 크게 향상할 수 있음
3B에서 훈련했을때 최종 성능측면에서 1.58bit와 FP16간 성능 차이가 매우 적다

가중치를 {-1, 0, +1}로 제한하기 위해, absmean 양자화 함수를 도입
- 성능이 줄어들지 않았나?
PPL(perplexity) 낮을수록 언어모델이 다음 단어에 대해 보다 정확한 예측을 수행함
동일한 모델 사이즈에서도 b1.58 모델이 LLaMA보다 우위임을 볼 수 있음



향후 발전 가능성
전문가 혼합(MoE)방식은 LLM에서 비용 효율적이 증명되었음
높은 메모리소비, 통신 오버헤드 유발
1.58bit LLM으로 해결할 수 있음
KV Cache : 토큰 생성 시 계산되는 Key/Value 텐서를 GPU메모리에 임시저장한 뒤 재사용하는것.
컴퓨팅 양을 줄이는 대신 텐서를 저장해야하기 때문에 trade off 발생
적은 메모리를 사용하는 1.58bit LLM은 이러한 문제를 해결할 수 있을것
모바일 기기와 같은 작은 하드웨어 장치에서 모델의 성능을 크게 향상시킬 수 있는 잠재력
또한 CPU에 더 친화적이므로, GPU가 들어있지 않은 기기에서도 효율적으로 작동할것
Groq 머신러닝 추론 가속기 와 같은 연구는
LLM을 위한 특정 하드웨어를 구축하기 위한 유망한 결과와 큰 잠재력을 보여줌
1bit를 위한 하드웨어와 시스템 설계가 디자인된다면 훨씬 더 좋은 발전이 가능할 것
Training Tips, Code and FAQ

- 왜 {-1, 0, 1} 이 세가지 항만 사용하는가?
{-1, 1} : BitNet (1bit짜리)를 구현했는데 성능이 구려요
{0, 1} : 최적화가 불안정하고 학습이 잘 안되요
{-2, -1, 0, 1} or {-2, -1, 0, 1, 2} 와 같이 추가적인 비트의 사용 : 삼항이랑 별 차이 없어요
- {-1, 0, 1} 값의 분포는?
대체로 균일함
- Full-precision 모델에서 post-training quantization(PTQ, 사후훈련 양자화) 사용은?
Full-precision을 훈련하고 8비트나 4비트까지 줄이는데는 성공적이었으나,
더 낮은 정밀도로 가중치를 양자화 하는데 어려움이 있었다.
실험적으로도 PTQ 훈련이 어렵다는것이 확인됨.
양자화를 할수록 크게 낮아지는 정확도, 개선이 불능하다고 판단되었다.
- 훈련이 빨라지나요?
추후 연구를 통해 훈련을 가속화 할 수 있는 잠재적인 방법들이 있을 것
- 더 큰 모델에서도 잘 되나요?
모델 크기가 커질수록 full-precision과 BitNet 1.58 사이의 loss가 줄어드는 것을 확인할 수 있다.
추세적으로 봤을 때, 더 큰 모델에서 더욱 효과적일 것
1.58비트 모델은 더 나은 일반화를 수행하고, overfitting 확률을 낮춘다.