논문 리뷰 - The Unreasonable Ineffectiveness of the Deeper Layers
심층 레이어의 비합리적인 비효율성
Abstract
PreTrained LLM에 대해 간단한 레이어 제거를 실증적으로 연구한 결과, 절반에 가까운 레이어를 제거한 후에도 성능저하가 최소한으로 나타남을 알게 되었다
모델들을 가지치기(prune)하기 위해, 레이어 간의 유사성을 고려하여 (자를) 최적의 레이어 블록을 식별한 후, 손상을 '치유(heal)' 하기 위해 약간의 Fine Tuning을 수행한다
이러한 결과는 레이어 제거 방법이 다른 PEFT(Parameter Efficient Fine Tuning) 전략을 보완하여 Fine Tuning에 필요한 계산 자원을 줄이고, 추론 시 메모리와 지연시간을 개선할 수 있음을 시사한다
또한 LLM이 레이어를 삭제했음에도 불구하고 견고한 성능을 유지한다는 것은 현재의 PreTraining 방법이 네트워크의 깊은 레이어의 파라미터를 적절히 활용하지 못하고 있거나, 얕은 레이어만이 지식을 저장하는 데 중요한 역할을 하고 있음을 의미한다
Introduction
최근 몇년동안 학습에 사용되는 자원의 급격한 증가로 LLM은 연구 산물을 넘어서 유용한 제품으로 발전했다
이러한 모델들은 학습이 완료된 후 대부분의 수명(주기)동안 추론모드에서 FLOPs(부동소수점 연산)을 수행할 것이므로,
LLM의 사전학습은 훈련과정에서의 효율성 뿐만 아니라 추론에서의 효율성 또한 고려되어야 한다
이미 학습된 모델은 양자화(Quantization), LoRA(Low Rank Adapters), 가지치기(Pruning)와 같은 사후학습 기술을 통해
미세조정 및 추론비용과 시간을 줄일 수 있다.
QLoRA는 파라미터의 4비트 양자화와 LoRA 미세조정을 결합하여 이러한 기술들을 함께 사용할 수 있도록 한다.
위와 같은 전략들을 기반으로, 본 연구에서는 가중치가 공개된 (Open Weight) LLM을 활용한 간단한 가지치기 전략을 연구하였다.
레이어간 유사성을 이용해 최적의 가지치기 레이어를 식별하고, 레이어를 제거 후 QLoRA를 사용하여 FineTuning을 통해 가지치기로 인한 불일치를 '치유'한다
주목해야할 점은 모델의 가장 깊은 레이어의 상당부분을 제거해도 Downstream Task 성능에 최소한의 저하만 발생한다는 것이다.
Llama-2-70B의 경우, 성능이 급격하게 감소되기 전까지 레이어의 절반가량을 제거할 수 있었다.

본 논문에서 강조하고자 하는 세가지는 다음과 같다:
1. 모델의 메모리 사용량과 추론시간은 제거된 레이어 수에 비례하여 감소한다.
2. 가지치기, PEFT, 양자화 등 효율성 방법(efficiency methods)는 서로 효과적으로 결합될 수 있다.
3. 깊은 레이어를 제거해도 모델의 견고성이 유지됨을 보아, 얕은 레이어가 지식을 저장하는 데 중요한 역할을 하고있다.
Method
어떻게 레이어 가지치기가 효과적일 수 있는가?
모델의 각 레이어는 잔차(residual) 네트워크 구조에 따라 이전 레이어의 출력에 작은 변화를 더해 생성된다.
이러한 작은 변화가 누적되어 최종 출력을 만들어낸다.
레이어 간의 변환은 서로 독립적이지 않으며, 이전 레이어의 출력이 다음 레이어의 입력으로 사용된다.
따라서 특정 레이어를 제거하면 레이어 간 연결이 변형된다.
일반적으로 원래 입력과 새 입력 간 불일치는 네트워크에 큰 손상을 줄 것이나, 초기 레이어 이후, 천천히 값이 변화하는 함수로 수렴하게 된다면, 깊은 레이어일수록 최종 출력에 미치는 영향이 적어질 것이다.
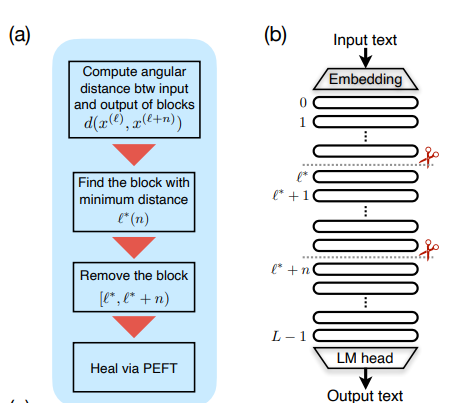
레이어 가지치기 알고리즘
0. 제거할 레이어의 수 n을 선택한다
1. 레이어 l의 입력과 레이어 l+n 의 입력 간의 각거리 d(x_l, x_(l+n)을 계산한다.
2. 각거리를 최소화하는 레이어 l*를 찾는다
3. 레이어 l* 부터 l* + n - 1 까지 n개의 레이어를 제거하고, 기존의 l* 입력을 (l*+n)번째 레이어에 연결한다.
4. 약간의 Fine Tuning을 통해 레이어 l* + n의 불일치를 치유한다. 이는 선택사항이다.
Results
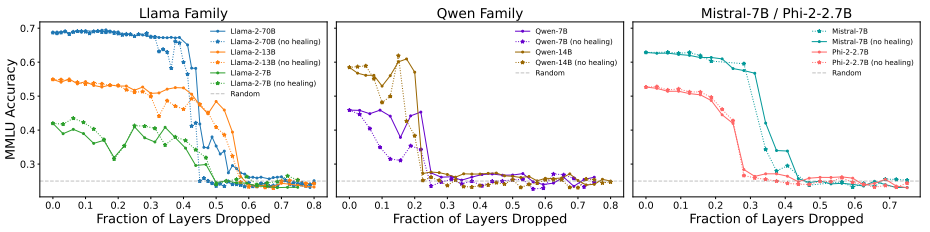
오픈소스 모델로 레이어를 제거한 수에 따른 MMLU 지표는 위와 같다.
QLoRA를 사용한 치유과정을 거친 모델들은, 치유과정 없이 레이어만 제거한 모델 보다 성능이 개선되었다.
또한 20~55%의 가지치기 비율까지는 성능이 robust하게 유지되었다.
모델 별 차이는 존재하나, 이 범위 내에서는 모델들이 여전히 유용한 성능을 보여줄 수 있음을 시사한다.

healing 과정 비수행 vs 수행 했을때의 Val loss 차이
healing을 진행하지 않았을 경우 손실값은 무작위추측(loss 1, 회색점선)과 동일해지지만,
healing을 진행했을 경우 급격한 변화 없이 모델의 견고함이 유지되며, loss의 연속성 또한 유지된다.
Llama와 같은 오픈소스 LLM의 발표 이후, LoRA 및 양자화와 같은 효율성 중심의 혁신이 이루어져 대형 LLM을 단일 GPU에서 fine tuning 가능하게 만들었다.
Llama-2-70B의 경우, 140GB 메모리를 소모한다.
4비트 양자화 및 50% 레이어 가지치기 후, 17.5GB 메모리만을 요구하게 되었다.
이러한 메모리 요구사항은 최첨단 오픈소스 LLM 모델이 소비자 수준의 GPU에서 효율적으로 실행 및 Fine Tuning될 수 있도록 한다.