[논문 리뷰] LG EXAONE 3.0 7.8B Instruction Tuned Language Model
EXAONE 3.0 7.8B Instruction Tuned Language Model
We introduce EXAONE 3.0 instruction-tuned language model, the first open model in the family of Large Language Models (LLMs) developed by LG AI Research. Among different model sizes, we publicly release the 7.8B instruction-tuned model to promote open rese
arxiv.org
https://huggingface.co/LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct
LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct · Hugging Face
EXAONE-3.0-7.8B-Instruct 👋👋 We have revised our license for revitalizing the research ecosystem.👋👋 Introduction We introduce EXAONE-3.0-7.8B-Instruct, a pre-trained and instruction-tuned bilingual (English and Korean) generative model with 7.8
huggingface.co
소개
LG에서 LLM 오픈소스모델을 공개했다고 한다. huggingface에서 바로 다운받아 사용 가능하다

특히 한국어작업, 수학/코딩/추론 분야에서 타 오픈소스 모델보다 높은 성능을 달성하였다고 한다.
Model Training
Model Architecture
최근 트렌드를 따라, EXAONE은 디코더로만 구성한 트랜스포머 아키텍처 (decoder-only transformer architecture)를 기반으로 만들어졌다.
최대 context 길이는 4096 토큰이고, Rotary Position Embedding (RoPE)와 Grouped Query Attention (GQA)를 사용하였다.

Tokenizer
토크나이저의 설계 선택은 학습과 문장생성의 효율성에 큰 영향을 미친다.
특히, 지원하는 언어 모델을 고려하는 것이 중요한데, EXAONE 3.0은 영어와 한국어를 지원하는 bilingual 모델이다.
두 언어의 이질적 특성을 고려하고, 특히 한국어의 교착어적(agglutinative language - 단어가 여러개의 형태소나 접사를 붙여서 만들어지는 언어 유형) 특성을 고려하여 한국어 말뭉치를 MeCab을 사용해 한국어 말뭉치를 미리 토큰화했다.
이후 BBPE(byte-level pyte-pair encoding) 토크나이저를 새로 학습시켰다.
이 결과, 영어에서는 기존 토크나이저와 비슷한 압축률을 보였으나, 한국어에서는 더 낮은 압축 비율울 보였다.
낮은 압축비율은 단어 당 생성되는 토큰 수가 적다는것을 의미하며, 이는 과도한 토큰화를 피할 수 있어 유리하다.

Pre - Training
데이터 원천과 속성을 다양화하고, 훈련 데이터의 중요성과 분포를 고려하여 샘플링 비율을 조정했다.
큐레이션 된 데이터를 바탕으로, 두번의 훈련을 진행했는데,
1. 일반 도메인에서의 성능 향상을 목표로 6조(6T) 토큰의 데이터를 사용해 모델을 훈련
2. 그 후, 추가적인 2조(2T) 토큰으로 모델을 훈련시켜 고급언어 기술 및 전문가 도메인 지식을 학습
데이터가 훈련에 적합한지 판단하기 위해 분류기를 만들어, 데이터 풀에서 고품질 도메인 데이터를 선택적으로 활용했다.
Post - Training
명령어 처리 능력 향상을 위해, 두 단계 후속훈련을 진행했다
1. Supervised fine-tuning (SFT)
모델이 새로운 작업에 잘 일반화 하려면 고품질의 지시 튜닝 데이터를 생성해야 한다.
그러나, 충분히 좋은 품질의 데이터를 수집하는 것은 어려운 과제이다.
이를 해결하기 위해, 서비스 지향적인 지시를 폭넓게 다루기 위한 다양한 주제와 지시 기능을 정의하고, 이를 바탕으로 실제 사용자 상호작용을 잘 반영하는 데이터셋을 생성했다.
2. Direct Preference optimization (DPO)
직접 선호 최적화를 통해 모델을 인간의 선호도에 맞추었다.
모델은 선호 데이터셋에서 선택된 응답과 거부된 응답 간의 보상 차이를 최대화하도록 훈련되었다.
오프라인 DPO는 사전에 구축된 선호 데이터를 사용해 모델을 훈련시키는 기술이다.
온라인 DPO는 오프라인 DPO를 통해 학습된 데이터 분포와 유사한 프롬프트를 구성하고, 모델이 응답을 생성하도록 하며, 이를 선호도에 따라 평가해 다시 훈련하는 방식이다.
오프라인/온라인 DPO를 순차적으로 적용했다.

모델에게 학습시킨 선호 데이터의 예시, chosen이 좋은 응답, rejected가 나쁜 응답으로, 모델은 두 응답 간 보상 차이를 최대화하도록 훈련되었다.
Evaluation


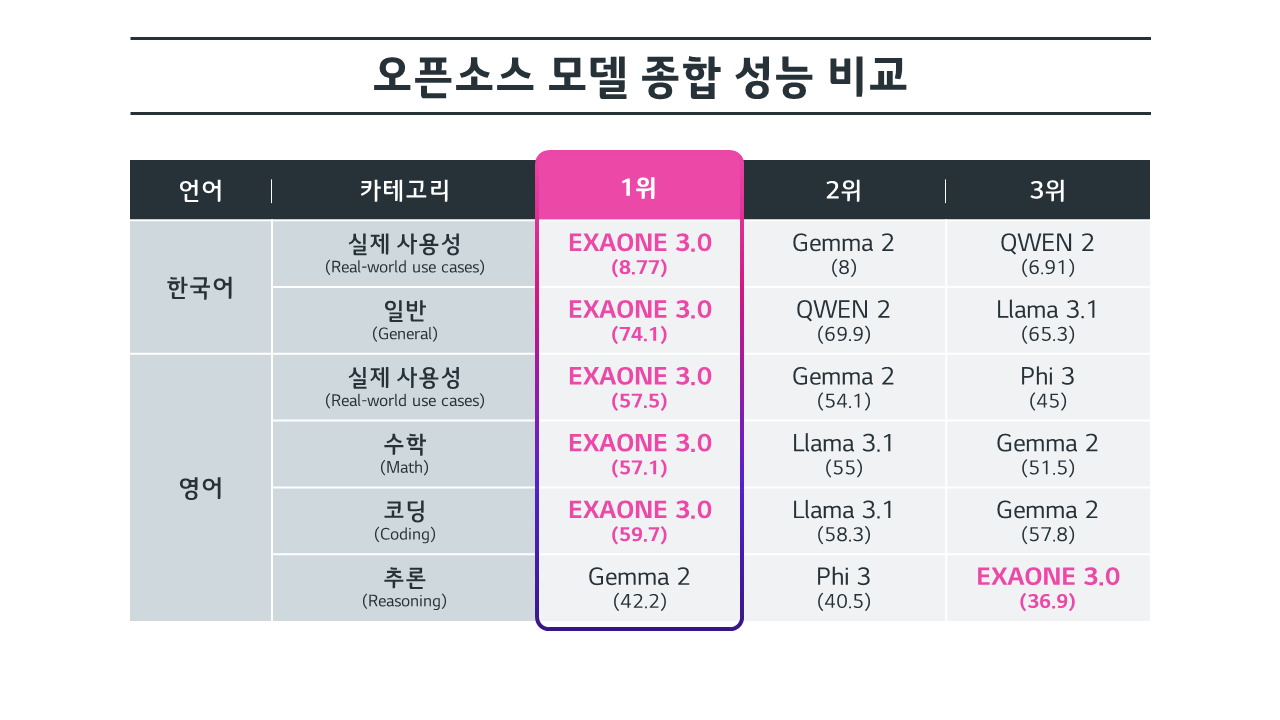
다양한 벤치마크에서 높은 성능을 보여준다.
챗봇 아레나 (실제 사람이 써보고 평가하는 플랫폼) 에서도 타 모델보다 높은 점수를 달성했다.
수학, 코딩 벤치마크는 Phi 3를 제외하고 다른 모델보다 높은 점수를 보여줬다.
추론에서는 3위를 달성했다.

복잡한 추론, 긴 컨텍스트 문장에서는 타 모델보다 부족한 성능을 보여줬다.


한국어 벤치에서는 압도적 1위를 차지했다.