BitNet b1.58 기술분석 : 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
BitNet의 소개와 구조에 관한 논문은 아래 링크에서 확인 가능합니다
https://beomsun0829.tistory.com/45
논문 리뷰 - The Era of 1-bit LLMs:All Large Language Models are in 1.58 Bits
논문링크 요약 비트넷과 같은 최근 연구는 1bit LLM(거대 언어 모델)의 새로운 시대를 열고 있다. 본 연구에서는 1-bit LLM의 변형인, BitNet b1.58을 소개한다. 이 모델은 모든 단일 매개변수 (또는 가중
beomsun0829.tistory.com
이번에 bitnet.cpp와 모델이 오픈소스로 공개되었습니다.
https://github.com/microsoft/BitNet
GitHub - microsoft/BitNet: Official inference framework for 1-bit LLMs
Official inference framework for 1-bit LLMs. Contribute to microsoft/BitNet development by creating an account on GitHub.
github.com
https://huggingface.co/1bitLLM
1bitLLM (1bitLLM)
huggingface.co
본 투고에서는 bitnet을 위한 커널을 다루고 있습니다.
Bitnet이란
1-Bit LLM은 모델의 가중치를 1비트 또는 저비트로 변환해 메모리 사용량과 전력 소모를 줄이는 동시에 성능을 유지하는 방법입니다.
대표적으로 BitNet과 BitNet b1.58은 이를 통해 초저비트 기반의 대형 언어 모델 추론이 가능하게 된 최신 기술입니다.
이러한 모델은 기존의 모델보다 메모리와 대역폭 효율성이 매우 뛰어나, 더 적은 자원으로도 강력한 성능을 유지할 수 있습니다.
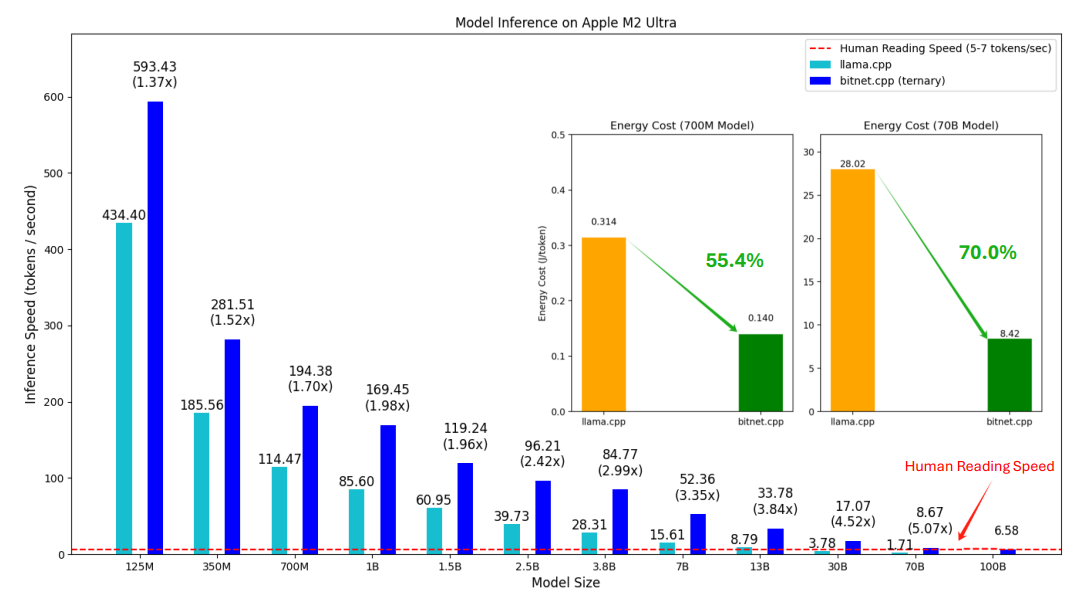
LLama vs Bitnet
모델의 크기가 커질수록 추론속도 차이가 점점 증가하는 경향이 보입니다.
이는 이전 논문 The Era of 1-bit LLMs:All Large Language Models are in 1.58 Bits에서 이미 설명된 바가 있는데,
부동소수점 곱셈연산이 필요하지 않은 bitnet은 모델의 scale에 따른 부하가 감소되어 모델 사이즈가 커질수록 효율적이게 됩니다.
Bitnet b1.58
BitNet b1.58은 1.58비트 (-1, 0, 1)로 양자화된 언어 모델로, 성능 저하 없이 모델을 매우 가볍고 빠르게 만들 수 있는 혁신적인 접근 방식을 채택하고 있습니다.
기존 모델 대비 속도와 에너지 소비 측면에서 우수한 효율성을 보이며, 다양한 로컬 장치에서 실행 가능한 것이 큰 장점입니다.
bitnet.cpp
bitnet.cpp는 BitNet b1.58 모델을 CPU에서 빠르고 정확하게 추론하기 위한 전용 프레임워크입니다.
이 프레임워크는 여러 최적화 커널을 제공하여 속도를 높이고 전력 소비를 줄이는데, x86 및 ARM CPU 아키텍처에 최적화 되었습니다
Kernel
bitnet.cpp는 <I2_S, TL1, TL2> 세개의 최적화된 커널을 제공하여, 다양한 CPU 아키텍처에서 효율적인 모델 추론을 지원합니다.
각각의 커널은 메모리 사용과 연산 속도 최적화에 중점을 두고 설계되었습니다.
I2_S 커널
- 2비트 가중치 표현: 각 가중치를 2비트로 압축하여 저장하고 필요 시 원래의 값으로 복원하는 방식입니다.
- 연산 효율성: 충분한 스레드를 활용하여 컴파일러가 효율적으로 파이프라인 명령을 생성할 수 있도록 설계되었습니다.
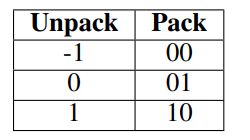
TL1 및 TL2 커널
- 루프업 테이블(LUT) 방식: TL1은 2자리를 4비트, TL2는 3자리를 5비트로 가중치를 압축하여 LUT를 통해 빠른 조회가 가능합니다.
- 메모리 대역폭 최적화: TL2는 TL1보다 높은 압축 비율을 가지고 있어, 제한된 메모리나 대역폭 환경에서 특히 효과적입니다.


Evaluation

추론 속도
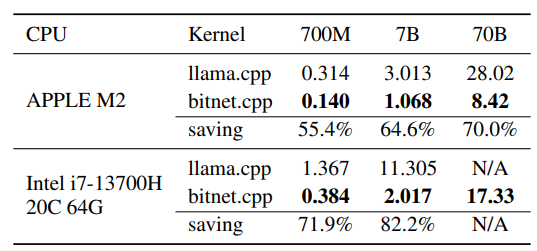
Apple M2에서 최대 5.07배의 속도 향상
Intel i7-13700H에서 최대 6.46배의 속도 향상
전력 소비
Apple M2에서 최대 70.0% 전력 절감
Intel i7-13700H에서 최대 82.2% 전력 절감