
서론
기존 기술의 문제점
LLM은 모델이 내포하고 있는 Parametric knowledge에 의존하고 있어, 사실과 다른 답변을 내놓는 경우가 있음
Retrieval-Augmented Generation(RAG)은 LLM + 연관된 지식을 검색해서 추가하는 방식으로 위 문제를 감소시킴
검색의 필요 여부에 상관없이, 고정된 숫자의 검색된 구절을 무차별적으로 검색하고 통합하는건
LM의 다재다능함을 악화시키거나, 도움이 되지 않는 응답을 생성할 수 있음
Self-RAG
Self-Reflective Retrieval-Augmented Generation(SELF-RAG)
언어모델이 필요에 따라 구절을 검색, 검색된 구절과 LM 자체 생성물을 반영하고 생성할 수 있도록
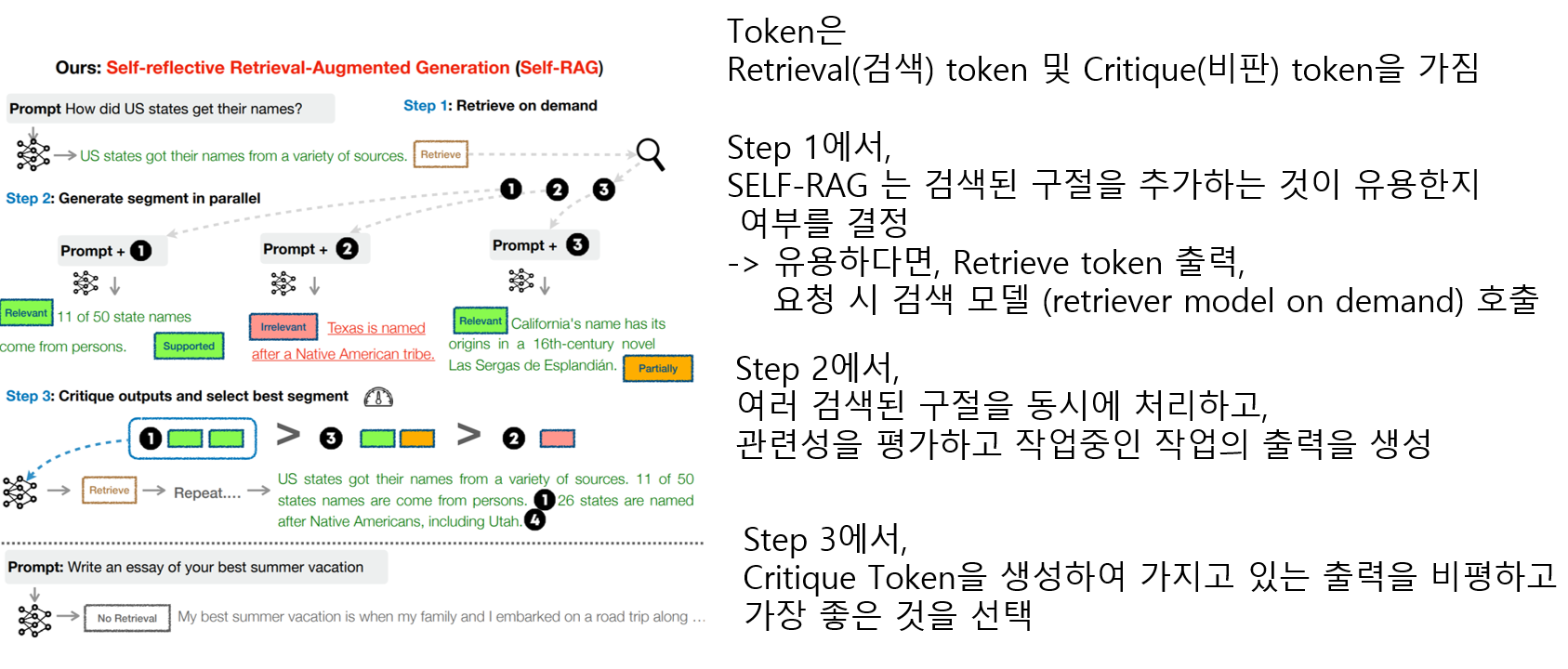
특수한 토큰 (Reflection token) 을 사용하여 훈련함
추론 단계에서 LM을 제어할 수 있게 되므로, 다양한 작업 요구 사항에 맞게 행동 조절 가능
SELF-RAG (7B 및 13B LM을 가지는..)의 경우 최신 LLM 및 검색 기반 모델보다 성능이 크게 향상됨
ChatGPT 및 llama보다 오픈 도메인 QA, 추론, 사실 검증 등에서 우수한 성능을 가짐
SELF-RAG의 동작
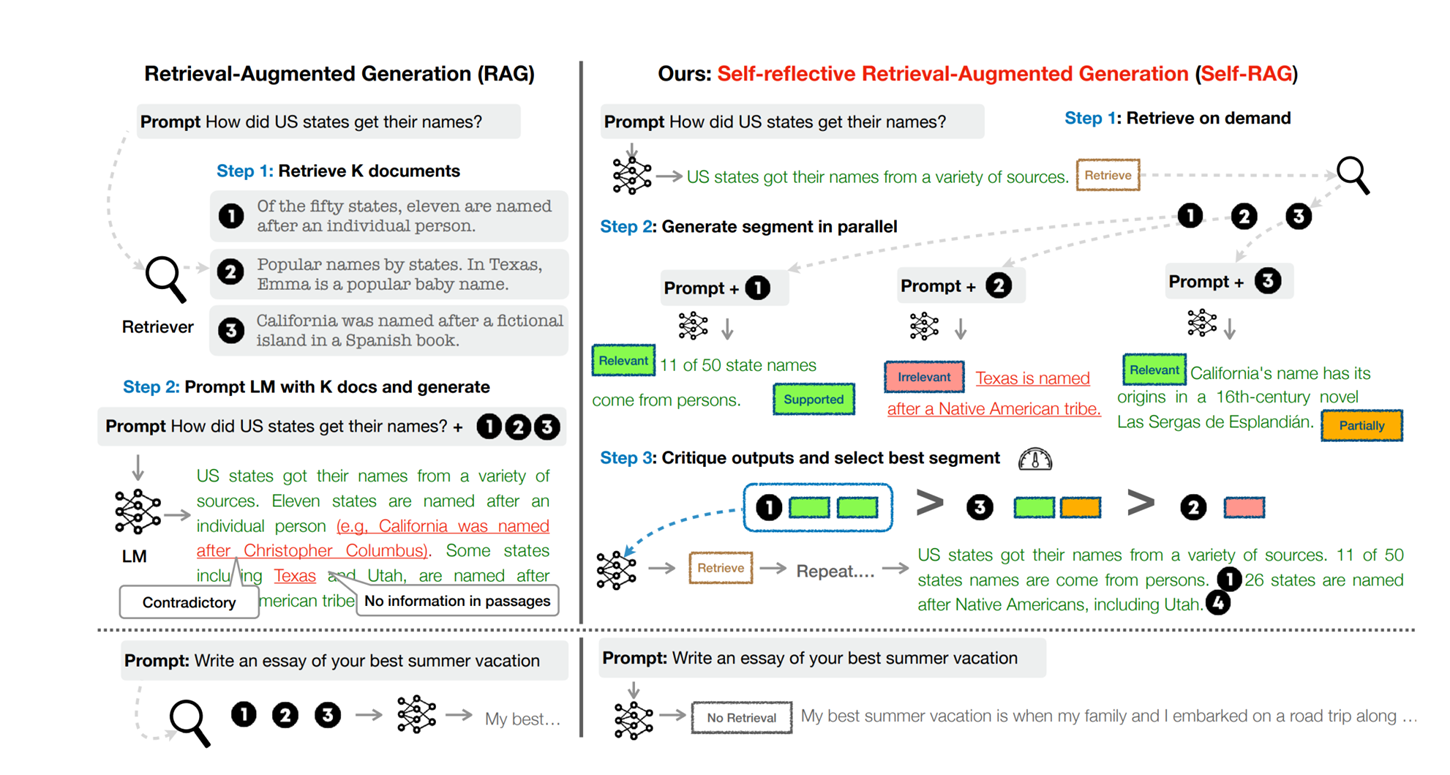

SELF-RAG의 동작
End-to-End 훈련은 LM이 필요시 검색된 구절을 참고하여 텍스트를 생성하고,
특수한 토큰을 생성하는 방법을 학습하여 출력을 비판하도록 함
Reflection Token 는 검색의 필요성을 나타내거나,
출력의 관련성, 지원, 또는 완전성을 확인
반면에, RAG 접근 방식은 인용된 출저에서 완전한 지원을 보장하지 않고 무차별적으로 구절을 검색

Retrieve : 검색기 R에서 정보를 검색할지 여부를 결정하는 과정
IsRel : 주어진 데이터 d가 입력 x를 해결하는데 필요한 정보를 포함하고 있는지
IsSup : 제공된 응답 y의 진술이 데이터 d에 의해 지원되는지 확인하는 검증 과정
IsUse : 문제 x에 대한 응답 y의 유용성을 평가하는 과정 (1~5, 높을수록 유용성 커짐)
조건에 상관없이 검색이 항상 초기 단계에서 고정된 과정으로 수행되는 RAG와 달리,
SELF-RAG는 Reflection Token을 도입하여 LLM을 더욱 적응적이고 지능적으로 만들고 있음

입력 : prompt x 및 이전 단계에서 생성된 출력 y<t
출력 : 다음 단계의 출력 yt
M이 주어진 x, y<t 에 대한 retrieve를 예측함
If Retrieve == yes,
x, y<t를 기준으로 검색기 R을 사용하여 관련된 텍스트 문서 D를 검색
M이 각 D 안에 포함된 각 d에 대해, IsRel을 예측함 : 해결할 정보를 포함하는지
M이 D에 포함된 각 d에 대해, IsSup 및 IsUse 를 예측함
IsRel, IsSup, IsUse를 기준으로 출력 yt 에 대한 순위를 매김
If Retrieve ==No,
Mgen이 주어진 x에 대한 yt 를 예측
Mgen이 주어진 x, yt 에 대한 IsUSE를 예측
M_gen에 대한 data creation
입력 : Input/Output 쌍인 {X,Y}에 대한 D
X,Y set 내 x,y에 대해,
Critique가 주어진 쌍에 대해 retrieve 토큰을 예측함
만약 예측이 되었다면,
검색기 R을 사용하여, {x,y} 쌍을 기준으로 관련 문단 집합 D를 검색,
집합 D 내 문단 d에 대해,
C가 각각의 d에 대해 IsRel을 예측함
C가 각각의 y,d 쌍에 대해 IsSup을 예측함
C가 각각의 d에 대한 IsUse를 예측함
d를 샘플링하여 선택
아니다? 예측못했다?
C가 제공된 x,y에 대해 isUse를 제공함
새로운 데이터를 생성하기 위한 확장된 형태 (x,y,d,r) 을 Dgen 에 추가함
SELF-RAG의 학습
SELF-RAG의 학습
Supervised된 데이터 수집과, Critique model C 와 Generator M의 훈련
Critique Model C의 훈련
1) 데이터의 수집
각 Segment에 대한 Reflection token을 수동으로 주석처리하는건 비용이 너무 많이 든다! (노가다)
GPT-4같은 LLM을 사용하면 피드백을 효과적으로 생성할 수는 있는데, API 비용이 또 많이 든다!
프롬프팅한 GPT-4를 통해 Supervised Data를 생성하여 reflection 토큰을 생성하게 함.
각 Reflection token 그룹에 대해, 원래의 훈련 데이터에서 무작위로 샘플링한 instance를 사용함
{Xsample, Ysample} ~ {X,Y}
GPT-4에, 아래와 같은 타입별 지시문을을 제공,
{Given an instruction, make a judgment on whether finding some external documents
from the web helps to generate a better response}
몇가지 샘플 예시와 함께 원본 작업 x와 출력 y에 따라 적절한 Reflection token을 텍스트로 예측하도록 함
수동으로 한 결과와 GPT-4의 Reflection Token 예측이 높은 확률로 일치함)
논문 저자는 4K~20K의 Supervised된 학습데이터를 수집하고 이를 결합하여
C(Critique model)의 훈련 데이터를 구성함

2) Critique 학습
훈련데이터 Dcritic 수집한 뒤에는, 사전 학습된 LM M을 사용하여 Critique Model C를 초기화하고,
조건부 언어 모델링 목표를 사용하여 아래와 같은 훈련 목표를 설정하고 Dcritic에서 훈련함
* 대부분의 Reflection Token 범주에 대해, GPT-4 기반의 예측과 90% 이상 일치하는 것을 목표로 함
이때, Critique Model C는 llama 7B 등의 생성모델등을 비록한 어떤 언어 모델로도 초기화할 수 있음

Generator Model M의 훈련
Data의 수집
입력과 출력 쌍 (x,y)이 주어진 경우, Self-RAG는 원래 출력 y 를 Retrieval 과 Critique Model을 사용하여 Supervised data를 생성함
각 segment yt에 대해, Critique 모델을 실행해서 추가적인 문단이 Generation을 향상시키는지 평가
검색이 필요한 경우, Retrieve Token = yes 가 추가되고, 검색기 R이 상위 K개의 문단 D를 검색
각 문단에 대해 C가 추가로 해당 문단이 관련있는지 평가하고 IsRel 을 예측함
관련된 문단이 있는 경우, 이 문단이 모델 생성에 도움이 되었는지 평가하고 IsSup을 예측
출력 y (또는 Y_T)의 끝에서, C는 전체적인 유용성 토큰인 IsUse를 예측,
Reflection Token이 포함된 증강된 출력과 원래의 입력 쌍이 Dgen 에 추가됨


2) Generator model의 학습
Reflection Token으로 증강된 Corpus를 훈련하여, Generator Model M을 학습함
Generator Model M은 Critique와 달리, 목표 출력 뿐만 아니라 Reflection token도 예측하도록 학습함
Loss 계산에 대한 검색된 text chunks를 마스킹하고 (<p>, </p> tag)
Reflection token {Crituque, Retreive}에 대한 set으로 Vocabulary V 로 확장함
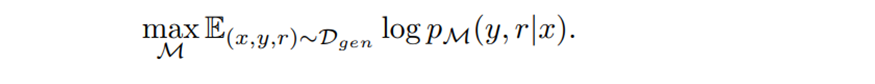
SELF-RAG 추론
Reflection 토큰을 생성해서 자신의 출력을 자체 평가하는 기능은 SELF-RAG가 추론 단계에서 제어 가능
추론 과정 중에, 상이한 목표들을 충족하기 위한 제어방식에 대한 설명
1. Treshold 값을 사용한 적응형 검색
: Retrieve 토큰을 예측하여, 문단을 언제 검색할지 동적으로 결정함.
SELF-RAG는 임계값(Treshold) 설정을 허용하므로,
Retrieve의 모든 출력 토큰에 대한 정규화된 값이 임계값을 초과하면 검색 Trigger하도록 할 수 있음
2. Critique Token을 사용한 Tree decording
각 Segnment 단계 t에서 검색이 필요할 경우, 검색기 R이 K개의 구절을 검색하고
생성기 M은 각 구절을 병렬로 처리해서 K개의 후보를 출력하는데,
각 단계 t에서 상위 B개의 Segment의 연속성을 얻기위한 Segment 수준의 beam search를 수행하고
최상의 sequence를 반환
Testing
DataSet
- pubHealth: 공공 건강에 대한 사실 검증
- ARC-Challenge: 과학 시험에서 생성된 다중 선택 추론 (다지선택 추론?)
- Pop-QA, TriviaQA-unfiltered: 짧은 문장 생성
- ALCE-ASQA: 긴 문장 생성
환경설정
LM : LLama2 7b 또는 13b
Critique Model C을 만들기 위해 llama2 7b 사용
검색기 모델 R : Contriever-MS MARCO 에서 상위 문서 5개를 사용,
Open Domain QA에 대해서는 웹 검색 엔진을 사용하여 상위 5개 문서 사용
- 추론 설정 : IsRel, IsSup, IsUse의 값을 1.0, 1.0, 0.5로 설정,
- 검색에 대한 임계값 : 0.2
+ Vllm 을 사용하여 추론 속도를 높임 (github의 코드 예제도 vllm을 사용함)
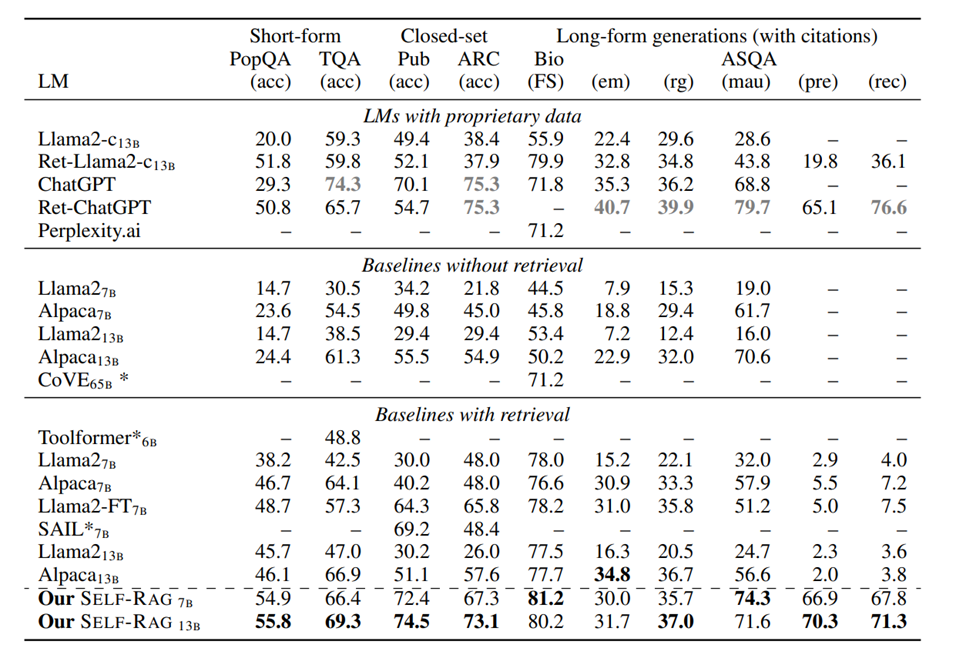
SELF-RAG는 모든 작업에서 Supervised된 LLM보다 상당한 성능 이점을 보여줌
특히, SELF-RAG의 7B 및 13B 모델은 Llama2 65B 모델을 프롬프팅하여 출력을 개선하는 CoVE를 능가함
검색 기반 Baseline과의 비교
여러 작업들에 대해 기존의 RAG를 능가하며,
비독점 LM 기반의 모델 중에서는 모든 작업에서 최고의 성능을 발휘함.
ASAQ에서, ChatGPT를 제외하고 인용 정확도와 재현율에서 현저히 높은 성능을 보여줌
7B가 13B보다 종종 더 나은 성과를 보인다는 것을 발견했는데,
더 작은 SELF-RAG 모델이 더 짧지만 정확하게 뒷받침된 출력을 자주 생성하려는 경향이 있었음
기타: 다른 모델들의 경우, 검색 기반의 경우에는 비검색 기반보다 큰 성능 향상을 보였으나,
검색된 구분 문자열을 단순히 복사하거나 추출할 수 없는 작업에 대해서는 제한된 솔루션을 제공했었음
(PubHealth, Arc-Challenge의 경우 성능이 크게 개선되지 않았다는듯)