
Abstract
해당 논문은 잠재 공간 (latent space)에서 사고하여 테스트 시점(test-time)에서 연산을 확장할 수 있는 새로운 언어 모델 아키텍처를 제안한다.
기존 모델들은 Chain-of-Thought (COT) 방식으로 더 많은 토큰을 생성하며 연산을 확장했다.
반면, 본 연구의 모델은 재귀 블록(recurrent block)을 반복적으로 실행하여 임의의 깊이로 연산을 진행한다.
특수한 훈련 데이터 없이도 동작하며, 작은 context window에서도 효과적인 학습이 가능하다.
언어로 표현하기 어려운 다양한 유형의 추론을 학습할 수 있다.
연속 공간에서의 사고를 통한 확장 (Scaling by Thinking in Continuous Space)
기존 접근법의 한계
초기 언어 모델 연구는 모델크기 확장을 통해 성능을 높였으나, 막대한 데이터와 연산비용이 필요했다.
최근에는 테스트 시점의 연산을 확장하여 (reasoning at test-time) 모델의 추론 능력을 강화하는 방법이 연구되고 있다
test-time이란, 모델의 training이 끝난 뒤 실행되는 시점을 의미
기존의 주류 접근법은 생각의 사슬, Chain-of-Thought(CoT) 학습을 통해 중간 계산을 언어화 하는 방식이었으나,
모든 내부 연산을 하나의 출력 토큰으로 투영해야 하는 제약은 비효율적이다.
연속적인 잠재 공간(latent space)에서 모델이 자체적으로 사고할 수 있다면 더 강력해질 수 있을것이다.
즉, 우리의 생각하는 중간 과정을 굳이 언어화 할 필요 없듯이, 모델도 생각을 잠재공간에서 진행한 후 최종출력만 토큰화시킨다는 것이 요지
Depth-Recurrent Language Model
모델에 재귀연산블록 (recurrent block)을 추가하여, 반복적인 연산을 통해 테스트 시점에서 깊이있는 사고가 가능하도록 한다.
특수한 훈련 데이터 없이도 학습 가능하며, 작은 context window에서도 효과적이다.
테스트 시점에서 연산을 확장할수록 추론 벤치마크 성능이 향상되었으며, 경우에 따라 35억개의 파라미터만으로 500억개의 파라미터를 가진 타 모델과 동등한 성능을 달성했다.
모델의 토큰 궤적(token trajectory) 분석 결과, 규모가 커질수록 모델이 숫자 연산을 수행할 때 잠재 공간에서 도형을 회전하는 등의 새로운 계산 패턴이 자발적으로 나타남을 확인했다.
Recurrent layer가 적용된 모델의 장점
특수한 훈련 데이터가 필요하지 않음
Chain-of-Thought 방식은 특정 도메인에서 긴 논증(demonstrations)를 학습해야 하는 반면,
잠재적 사고 (latent reasoning)는 일반적인 학습 데이터로 훈련할 수 있다.
CoT 모델보다 메모리 사용량이 적음
CoT 모델은 매우 긴 context window를 요구하므로, 토큰 병렬화 (token parallelization) 등의 특수한 훈련 기법이 필요할 수 있다.
그러나, Recurrent Depth 모델은 더 적은 메모리로도 훈련 및 추론이 가능하다.
기존 트랜스포머보다 연산 효율이 높음
동일한 파라미터 수에서 더 많은 FLOPs(Floating Point Operations)를 수행할 수 있다.
단순한 암기 방식이 아닌 '사고'를 학습하도록 유도
논리, 추상화, 메타 전략 학습을 강화하여, 문제 해결을 위한 사고 과정 자체를 학습하게 만든다.
기존 연구에서 재귀적 학습 방식이 복잡한 알고리즘 학습에 강점을 보임이 입증된 바 있다.
잠재적 사고와 인간의 사고방식
잠재적 사고 (latent reasoning)는 인간의 사고 과정 중 언어화되지 않는 요소를 포착할 수 있다.
- 공간적 사고 (spatial thinking), 물리적 직관 (physical intuition), 운동 계획 (motor planning)
재귀적 프로세스를 여러 번 반복함으로써, 기존의 선형적 사고 (linear thinking) 방식이 아닌, 다차원 벡터 공간에서 깊이 있는 탐색이 가능해진다.
이를 통해 새롭고 복잡한 추론 행동 (complex reasoning behavior)이 자연스럽게 나타날 수 있다.
확장 가능한 재귀적 구조 (A Scalable Recurrent Architecture)
본 논문에서는 latent recurrent depth를 활용한 트랜스포머 모델 아키텍처를 제안하며, 구조와 설계선택, 소규모 실험에 대해 서술한다.
거시적 설계 (Macroscopic Design)

구성
모델은 세 가지 주요 블록으로 구성된다.
1. Prelude, P
입력 데이터를 잠재공간 (latent space)로 임베딩하는 역할을 수행
2. Recurrent Block, R
중심 연산을 담당하며, 재귀적으로 상태 (state)를 변경함
3. Coda, C
최종적으로 잠재 공간에서 출력을 생성 및 변환하고, 예측 헤드 (prediction head)를 포함
연산과정
모델의 연산과정은 아래와 같다.

1. 입력 시퀀스 $x \in V^n$를 Prelude 블록에서 임베딩 -> $e = P(x)$
2. 초기 상태 $s_0$를 정규 분포에서 무작위로 샘플링 -> $s_0 \sim N(0, \sigma^2I_{n\cdot h})$
3. 재귀블록을 r번 반복하여 잠재 상태$s_i$ 업데이트 -> $s_i = R(e, s_{i-1})$
4. 마지막 상태를 사용해 출력 확률을 계산 -> $p = R(s_r)$
이 과정은 무한히 많은 iteration을 수행할 수 있는 구조를 형성한다.
설계 동기 (Motivation for this Design)
재귀적 설계는 안정적인 반복 연산 (Stable Iterative Operators)를 학습하는 최소한의 구조를 제공한다.
Gradient Descent과 유사한 방식으로 동작하며, 초기 상태에서 출발하여 반복적으로 연산을 수행한다.
매 반복 단계에서 임베딩된 입력 데이터 e를 지속적으로 주입해야 연산이 안정적으로 수렴할 수 있다.
만약 e를 처음에만 제공하고 지속적으로 주입해주지 않으면, 경계 조건 (boundary conditions)에 의존하게 되어 불안정성이 증가한다.
경계 조건: 초기 상태 또는 특정 제한된 상태에서만 성립하는 조건.
모델이 입력데이터를 처음 한번만 받는다면, 재귀 연산 과정에서는 초기 입력 상태에 의해 결정된 경로를 따를 수 밖에 없음
이는 연산이 단순히 초기값에 의해 고정될 수 있음
확산 모델 (Diffusion Models)과의 차이점
Diffusion Models와 유사한 구조를 가짐
Diffusion Model에서 사용하는 noise를 추가하는 방법을 시도했으나, 훈련 목표 (training objective)와 충돌하여 도움이 되지 않았다.
또한, 매 단계에서 개별적으로 업데이트 하는 구조도 실험했으나, 경로 독립성 (path independence)를 저해하여 일반화 성능이 저하되었다.
경로 독립성: 연산, 최적화, 학습 등의 최종 결과가 초기상태나 중간과정의 특정 경로에 의존하지 않는 성질
즉, 출발점이 다르더라도 같은 목표에 도달할 수 있는 성질
경로 독립성이 없으면 일반화 성능 저하, local minima에 빠짐, 수렴속도 저하 등 여러 문제가 발생할 수 있음
미시적 설계 (Microscopic Design)
모델의 각 블록은 표준 트랜스포머 레이어 디자인을 따른다.
각 레이어는 다음과 같은 요소로 구성된다:
- casual self-attention block, RoPE(Rotary Positional Embeddings)를 사용하여 위치 정보를 반영
- Gated SiLU MLP
- RMSNorm
- query와 key에만 학습 가능한 bias 적용, 다른 부분에는 bias를 사용하지 않음
재귀적 연산 안정성을 위한 "sandwich" 구조

$n_i$는 정규화 계층
재귀적 연산을 대규모로 훈련하려면 이 정규화 기법이 필수적임을 소규모 실험을 통해 확인하였다.
주요 블록별 세부 설계
Prelude, P
입력 토큰 $x$를 임베딩 행렬 $E$와 스케일링 값 $\gamma$를 사용해 변환:
e=γE(x)
e=γE(x)
변환된 임베딩 $e$를 여러 개의 서론 레이어($l_P$)에 전달하여 전처리 수행.
Recurrent Block, R
입력 임베딩 $e$와 이전 상태 $s_i$를 연결(concatenation)하여 매핑(matrix A)를 수행:
$A : \mathbb{R}^{2h} \to \mathbb{R}^h$
소규모 모델에서는 덧셈(addition) 방식도 가능했으나, 대규모 모델에서는 연결(concatenation) 방식이 더 효과적이었음.
변환된 벡터를 $l_R$개의 트랜스포머 레이어를 통과시킴.
최종적으로 RMSNorm($n_c$)을 사용하여 출력을 정규화.
Coda, C
$l_C$개의 트랜스포머 레이어를 거쳐 최종 출력을 생성.
정규화($n_c$) 후, 어휘 집합($V$)으로 투영(projection)하여 최종 예측을 수행.
어휘 투영에는 공유된 임베딩 행렬(Shared Embedding, $E_T$)을 사용.
모델 아키텍처 요약 및 스케일링
모델 아키텍처는 세 가지 주요 요소의 레이어 개수(lP, lR, lC)와 재귀 반복 횟수(r)에 의해 결정된다.
소규모 실험:
(1, 4, 1) 형태의 모델 (P, R, C)
hidden size $h = 1024$
대규모 모델:
(2, 4, 2) 형태의 모델
hidden size $h = 5280$
실제 트랜스포머 레이어는 8개지만, 재귀 반복 횟수 $r = 32$일 경우, 효과적인 깊이는 $2 + 4r + 2 = 132$층이 된다.
즉, 재귀 블록의 반복을 통해 기존 고정 깊이 트랜스포머보다 훨씬 깊은 네트워크를 구성할 수 있다
이 방식은 기존 연구에서 제안된 고정 깊이(fixed-depth) 트랜스포머보다 훨씬 깊은 계산 체인을 생성할 수 있도록 해준다
훈련 목표 (Training Objective)
모델이 test-time에서 재귀 반복 횟수를 확장할 수 있도록 학습하기 위해, 훈련 과정에서 반복 횟수를 랜덤하게 샘플링한다.
랜덤 샘플링된 반복횟수에 대한 손실 함수의 기댓값을 최적화하는 방식을 사용한다.
목표는 모델이 다양한 반복횟수에서 안정적으로 작동하도록 훈련하는 것이다. 이를 unrolling이라고 한다

훈련 시 연산량과 메모리 사용량을 줄이기 위해, 마지막 k개의 반복(iteration)에 대해서만 역전파(backpropagation)을 수행한다.
이를 통해 반복 횟수 (r)에 관계없이 역전파에 필요한 메모리를 일정하게 유지할 수 있다.
Prelude Block은 모든 반복에서 입력을 받으므로, 모든 단계에서 기울기 업데이트를 받을 수 있다.
이는 RNN의 Truncated Backpropagation Through Time (TBPTT)와 유사한 방식이나,
본 논문에서는 시간이 아니라 깊이 (depth) 방향으로 재귀적 연산을 수행한다는 차이점이 있다.
Training
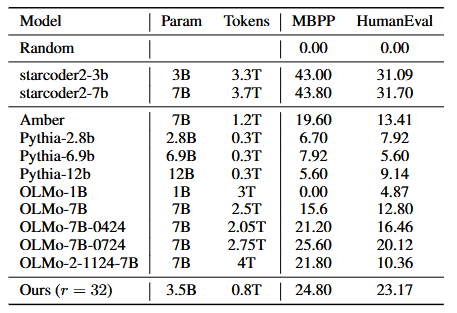
세부적인 파라미터, 토큰화 방법론 등은 생략하겠습니다.

훈련 중 초기 두번의 훈련 (Bad Run 1, Bad Run 2)가 실패했었음
Bad Run 1 - 은닉 상태 붕괴 (hidden state collapse)
모델이 동일한 hidden state를 모든 토큰에 대해 예측하여 학습이 중단되었다.
토큰 간 hidden state의 상관 관계 (Corr)가 1에 가까워짐, 모델이 유의미한 정보를 학습하지 못하고 모든 입력을 같은 방식으로 처리했다.
원인:
- iteration마다 hidden state가 강하게 혼합되면서, 동일한 상태로 수렴됨.
- 매개변수가 없는 RMSNorm을 사용하여 정규화 층이 효과적으로 작동하지 않음.
- embedding scale $\gamma$가 없어서 초기 hidden state가 불안정하게 설정됨.
- 어댑터 블록 ($A(s, e) = s + e$) 이 학습가능한 매개변수가 없음 (parameter-free)
입력 상태 s와 입력 벡터 e를 단순히 더하는 방식은 학습가능한 매개변수가 없으며, 훈련을 통해 최적화되지 않음
Bad Run 2 - 재귀 연산이 효과적으로 활용되지 못함
모델이 초기 학습에서는 정상적으로 작동했으나, test-time에서 재귀 연산을 확장할 때 성능향상이 나타나지 않았다.
즉, 1회 반복과 32회 반복 성능차이가 거의 없었다는 것. Test-Time Compute Scaling이 무효화되었다.
원인:
- 초기에는 토큰 간 hidden state의 상관관계가 1.0에 가깝게 급격히 증가했으나, 이후 회복됨
- 그러나 모델이 초기에 상태 (s)를 무시하는 학습패턴을 형성하여, 이후 iteration이 더해져도 성능이 향상되지 않음
- 즉, 모델이 초반에 입력상태를 무시하는 local minimum에 빠짐
결국 재귀적 연산을 제대로 활용하지 못하는 모델이 되어 학습에 실패했다.
Main Run - 최종 성공
샌드위치 구조의 정규화를 유지하여 hidden state의 붕괴를 방지했다.
embedding scale $\gamma$를 추가하여 초기 hidden state를 안정화 시켰다.
학습 가능한 어댑터 블록 (A, (s, e))를 적용하여 입력상태 (s)를 효과적으로 반영했다.
학습률 (learning rate)를 감소시켜 초기 학습이 안정적으로 진행되도록 조정하였다.

왼쪽 그래프에서는 Training Loss가 성공적으로 감소하며 수렴하는 형태를 보여준다.
오른쪽 Validation Perplexity (검증 혼란도) 그래프에서는 서로 다른 Recurrence Depth에 따른 검증 혼란도 차이를 보여준다.
재귀 횟수가 많을수록 검증 혼란도가 감소한다.
벤치마크



Recurrence에 따른 각 벤치마크 퍼포먼스 증가
재귀적 사고를 적용한 모델이 비재귀 모델 대비 큰 성능 향상 폭을 보였다.
특히 GSM8K(수학) 과 ARC Challenge(추론) 문제에서 큰 성능 향상을 보였다.
쉬운 문제 (SciQ)에서는 재귀가 큰 차이를 만들지 않았다.


재귀 연산 횟수가 증가할수록 ARC Challenge 정확도가 향상되었다.
Few-Shot 예제 수가 많을수록 정확도가 더 높아졌다.
0-Shot 설정에서는 재귀 연산이 8 이상 증가해도 성능이 거의 향상되지 않았다.
이는 정보가 부족한 상태에서는 추가연산이 큰 효과를 발휘하지 못함을 시사한다.