

Generative Adversarial Nets (GAN)
생성적 적대 신경망
생성자 (Generator)와 판별자 (Discriminator)의
적대적 학습 (Adversarial learning)을 통해 성장하는 모델
'간'으로 발음하는 분이 계시는데 '겐'입니다 (제작자 오피셜)
GAN의 구성요소
입력 영상의 [Real] or [Fake]를 판별하는 Discriminator (판별자)


실제 이미지의 판별결과: $$( \mathbb{E}_{x \sim p_{\text{data}}(x)} \left[ \log D(x) \right] )$$
x는 실제 데이터에서 샘플링 된 이미지, D(x)는 판별자가 이 이미지가 진짜라고 판단하는 확률
판별자가 실제 이미지를 진짜라고 올바르게 판단하도록 유도
가짜 이미지의 판별결과: $$( \mathbb{E}_{z \sim p_z(z)} \left[ \log(1 - D(G(z))) \right] )$$
G(z)는 임의의 변수 z에 대해 생성자 G가 생성한 가짜 이미지, D(G(z))는 판별자가 이 가짜이미지를 진짜라고 판단할 확률
둘을 더하면 판별자가 실제 이미지를 진짜로, 가짜 이미지를 가짜로 구분하도록 학습하는 수식이다.
Discriminator를 속일 수 있는 영상을 만드는 Generator (생성자)

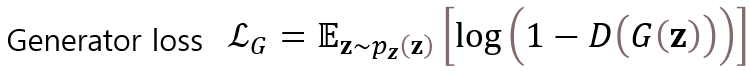
Progressive Growing (PG) GAN
고화질 영상을 생성하기 위한 전략 : progressive growing



PGGAN(Progressive Growing of GANs)은 이미지 생성을 점진적으로 향상시키는 방식의 GAN 모델
이 방식은 낮은 해상도에서 시작하여 높은 해상도로 점진적으로 업스케일링하면서 세부 사항을 추가해가는 방식으로 동작
이를 통해 고해상도의 이미지를 더 안정적으로 생성할 수 있다
StyleGAN




Mapping Network
- 랜덤 노이즈: 생성 과정은 무작위 노이즈 벡터에서 시작
- Mapping Network: 랜덤 노이즈 벡터를 스타일 벡터로 변환
스타일 벡터는 생성할 이미지의 특성을 제어하는 역할을 하며, 각 레이어에서 이미지의 다양한 시각적 요소를 반영
Affine Transform과 Broadcast
- Affine Transform (A): 스타일 벡터는 각 레이어에서 affine 변환을 통해 특정한 형태로 조정, 이를 통해 스타일 벡터가 각 레이어에 적절하게 반영될 수 있도록 함
- Broadcast (B): 조정된 스타일 벡터가 레이어의 feature map에 broadcast되어 각 픽셀에 동일한 스타일 정보를 적용할 수 있음
Adaptive Instance Normalization (AdaIN)
AdaIN은 각 레이어의 feature map에 스타일 벡터가 반영되도록 함. 이 때, 스타일 벡터가 feature map의 평균과 표준편차를 조절하여 전체적인 이미지 스타일을 통제
$$( \text{AdaIN}(x, y) = \sigma(y) \left( \frac{x - \mu(x)}{\sigma(x)} \right) + \mu(y) )$$
- 여기서 x는 feature map, y는 스타일 벡터
- $\mu(x)$와 $\sigma(x)$는 feature map의 평균과 표준편차이며, $\mu(y)$와 $\sigma(y)$는 스타일 벡터의 평균과 표준편차
- AdaIN은 feature map을 정규화한 뒤 스타일 벡터의 평균과 표준편차로 다시 스케일링하여 스타일이 반영된 feature map을 생성

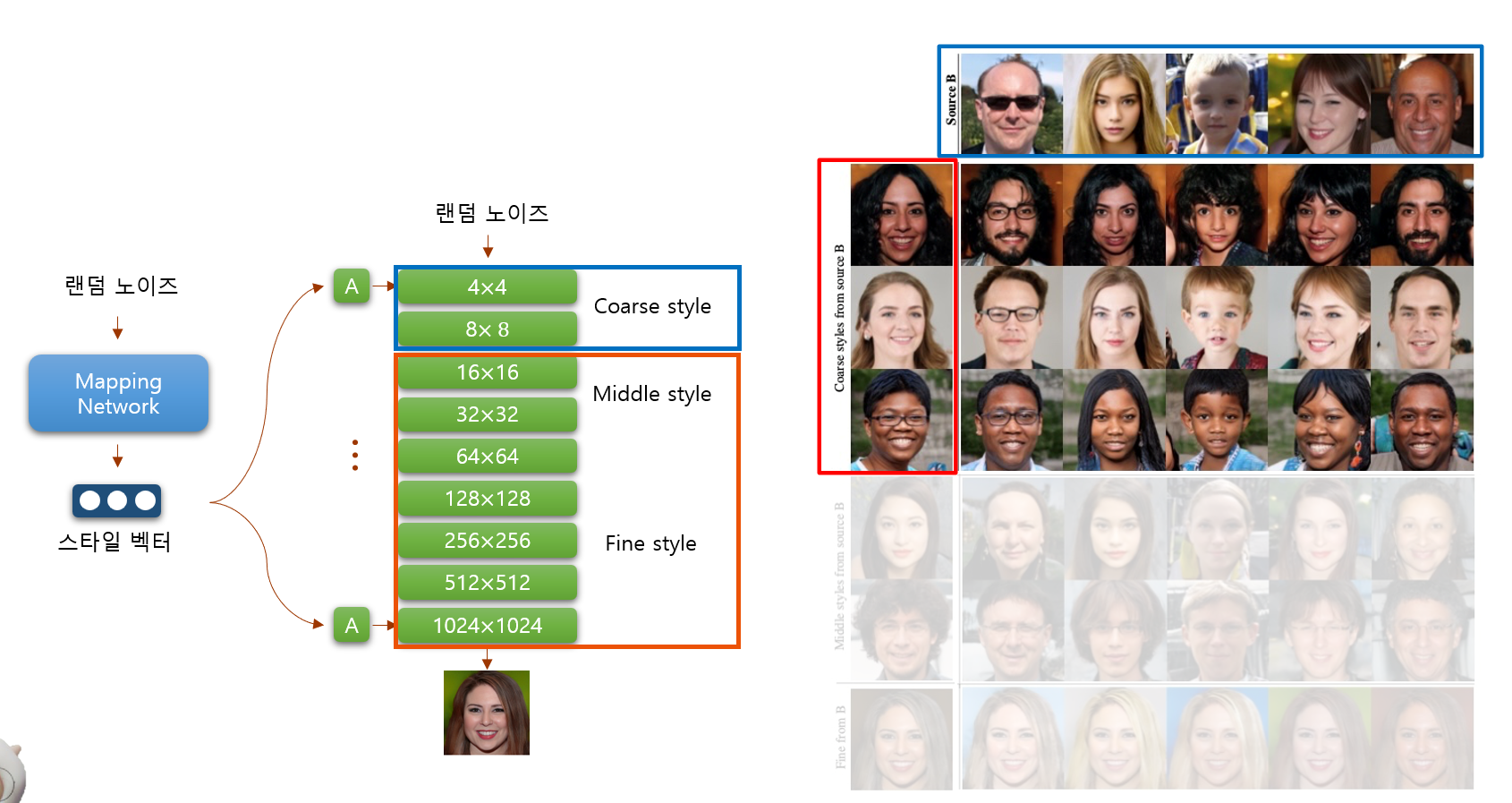


각 레이어가 서로 이미지의 다른 시각적 특성을 담당하고 제어하고 있음
Coarse style
저해상도의 초반 레이어들은 얼굴의 전반적인 구조, 얼굴 윤곽과 같은 큰 특징을 제어
얼굴 모양이나 비율과 같은 전체적인 형상 정보가 여기에서 결정
Middle style
중간 레이어들은 눈, 코, 입 등의 얼굴 부위에 대한 세부적인 특징을 제어
Fine style
고해상도의 후반부 레이어들은 피부 결, 머리카락 색상, 작은 주름과 같은 미세한 텍스처와 색상을 조정
이 영역에서는 실제 사람의 피부 질감이나 머리카락의 세부적인 색조를 표현