
최근 공개된 OpenAI의 o1모델에 큰 영향을 주었다고 알려진 논문입니다.
OpenAI연구진은 언어모델의 수학 및 추론능력을 크게 향상시킨 방법론을 이미 1년전에 공개했습니다.
0. Abstract
최근 몇년간, LLM의 복잡한 다단계 추론 성능이 크게 향상되었으나, SOTA 모델들도 여전히 논리적 오류를 발생시킨다.
신뢰성 있는 모델을 훈련하기 위해, 결과 감독(outcome supervision, 결과에 대한 피드백을 제공)과 과정 감독(process supervision, 중간 추론 단계에 대한 피드백 제공)을 비교할 필요가 있다.
해당 논문의 저자는 자체적인 조사를 통해 과정 감독이 결과 감독보다 MATH 데이터셋 문제를 훨씬 잘 해결한다는 것을 발견했다.
또한 능동 학습(active learning)이 과정 감독의 효율성을 크게 향상시킨다는 것을 보여주었다.
관련 연구를 위한 80만개의 단계별 인간 피드백 레이블 (step-level human feedback label)로 구성된 PRM800K 데이터셋을 공개한다.
1. Introduction
LLM은 단계적 사고 (chain-of-thought)를 통해 복잡한 다단계 추론을 요구하는 작업을 해결할 수 있었다.
그러나 SOTA모델 조차도 불확실한 상황에서 잘못된 정보를 생성하는데, 이를 환각 (hallucinations) 이라고 한다.
LLM의 환각 문제는 다단계 추론이 필요한 분야에서 특히 문제가 되는데, 하나의 논리적 오류만으로도 정답으로부터 벗어날 수 있기 때문이다.
이로 인해 환각을 감지하고 완화하는 것은 LLM의 추론능력을 향상시키기 위해 필수적이다.
환각을 줄이기 위한 효과적인 방법 중 하나는 보상 모델 (reward model)을 훈련하여 바람직한 출력과 그렇지 않은 출력을 구별하도록 시키는 것이다.
이러한 기법은 유용하지만, 결과 시스템의 신뢰성은 보상 모델 자체의 신뢰성에 달려있다.
따라서 신뢰할 수 있는 보상모델을 효과적으로 훈련하는 방법을 연구하는 것이 중요하다.
Solving math word problems with process-and outcome-based feedback 에서는 보상 모델을 훈련하는 두 가지 방법인 결과감독과 과정감독을 설명한다.
결과 감독 보상 모델 (Outcome-supervised Reward Models, ORM)은 단계적 사고 이후 최종 결과만을 사용해 훈련되는 반면,
과정 감독 보상 모델 (Process-supervised Reward Models, PRM)은 단계적 사고 중 각 단계에 대한 피드백을 받는다.
과정 감독이 선호되는 이유는 아래와 같다.
1. 과정 감독은 발생한 오류의 정확한 위치를 명확히 알려주는, 보다 정밀한 피드백을 제공한다.
2. 인간이 해석하기 더 쉬워진다.
3. 인간이 승인한 사고의 흐름을 따르는 모델에 보다 직접적으로 보상을 제공한다. (인간의 사고과정에 유사하도록 학습)
논리적 추론 영역에서 결과감독을 받은 모델은 종종 올바르지 않은 추론을 사용해 올바른 결과에 도달할 때도 있다.
과정 감독을 통해 이러한 잘못된 행동을 완화할 수 있다.
이러한 장점에도 불구하고, 위 논문에서는 초등 수학 분야에서 결과감독과 과정감독이 비슷한 최종 성능을 나타낸다고 밝혔다.
본 논문에서는 더 좋은 모델의 사용, 더 많은 인간 피드백 활용, 더 어려운 MATH 데이터셋에서 훈련 및 테스트를 진행하여 결과감독과 과정감독의 상세한 비교를 수행한다.
본 논문의 기여는 아래와 같다:
1. 과정 감독이 결과 감독보다 훨씬 신뢰할 수 있는 보상 모델을 훈련할 수 있음을 보여준다.
2. 대형 보상모델이 소형 보상모델을 감독하도록 시켰더니 인간의 감독성능을 근사하였으며, 이를 사용해 대규모 데이터 수집 실험을 효율적으로 수행할 수 있음을 보인다.
3. active learning이 과정 감독의 데이터 효율성을 2.6배 향상시킨다는 것을 입증했다.
4. 과정감독 분야의 연구 촉진을 위해, PRM800K 데이터셋을 공개했다.
2 Methods
Solving math word problems with process-and outcome-based feedback 와 유사한 방법론을 따라 결과 감독과 과정 감독을 비교했다.
결과 감독에서는 MATH 데이터셋의 모든 문제에 답이 있었기 때문에, 인간의 개입이 필요가 없었다.
반면 과정 감독은 자동화 할 수 있는 간단한 방법이 없는데, 모델이 생성한 풀이과정 각 단계의 정확성을 인간 데이터 라벨러가 직접 라벨링하게 하였다.
대규모와 소규모로 체제를 나누어 실험을 진행했다.
대규모 실험에서는 모든 모델(ORM, PRM)을 GPT-4의 파인튜닝 버전을 사용하여 모델의 최대 성능을 끌어내는 데 중점을 두었다. 그러나 이러한 보상 모델의 훈련은 여러 이유로 인해 직접 비교가 불가능하다. (자세한 내용은 3장에서)
이를 해결하기 위해, 소규모 실험에서도 모델을 훈련하여 직접적인 비교를 수행했다. 인간 피드백의 높은 비용 의존도를 줄이기 위해, 대규모 모델을 사용하여 소규모 모델 훈련을 감독하도록 했다.
2.1 Scope (범위)
테스트에 사용할 모델 generator를 만든다. 강화 학습으로 generator의 성능을 개선하는 것을 피했는데,
이는 generator의 성능이 중요한것이 아닌 그 답을 채점하는 보상 모델의 성능이 중요하기 때문이다.
보상 모델은 generator가 생성한 솔루션 중 최상의 솔루션을 선택하는 능력으로 평가된다.
generator가 생성한 풀이 중 보상모델이 가장 높은 점수를 준 풀이가 그 보상모델의 최종 답이 되며, 신뢰할 수 있는 보상모델은 더 자주 올바른 풀이를 선택하게 된다.
2.2 Base Model (기본 모델)
모든 대형 모델은 GPT-4의 파인튜닝 버전이다. 기본 모델이므로 오직 다음 토큰을 예측하기 위한 말그대로 GPT (generative pre-trained transformer) 이며, 인간 피드백을 통한 강화학습(RLHF)을 수행하지 않았다.
소형 모델은 GPT-4와 같은 구조를 가지고 있으나, 200배 적은 연산량을 사용하여 사전훈련 시켰다. (학습 데이터가 더 적음)
사전훈련 단계에서 15억개의 토큰을 가진 MathMix 데이터셋으로 추가적인 파인튜닝을 수행했다.
이 작업은 구글 연구팀이 수행한 연구 Solving Quantitative Reasoning Problems with Language Models 의 연구결과와 같이 모델의 수학적 추론 능력을 향상시킨 다는것을 확인했다.
2.3 Generator (생성기)
generator는 추론 과정을 쉽게 확인할 수 있도록 훈련하여 각 풀이과정을 줄바꿈으로 구분된 단계별 형식으로 생성하도록 했다.
MATH 문제에 대해 올바른 풀이과정을 생성한 경우를 골라 한번의 epoch만 미세조정을 수행했다.
이는 generator에게 새로운 기술을 가르치는 것이 아니라, 답안 생성 형식을 가르치기 위함이다.
2.4 Data Collection (데이터 수집)
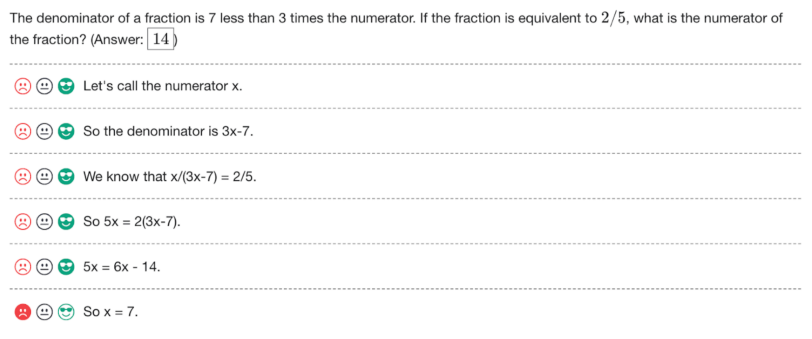
대형 모델 generator가 생성한 MATH 문제의 단계별 풀이과정을 인간 데이터 라벨러에게 제시한다.
인간 라벨러는 각 풀이과정 단계에 대해 긍정적/부정적/중립적 라벨을 지정하게 된다
위 그림에서, 풀이과정이 정확했기 때문에 인간 라벨러는 긍정적인 라벨을 할당했으나, 마지막 수식에서는 오답을 도출했기 때문에 부정적 라벨을 할당하게 된다.
인간 라벨러의 효율적인 사용을 위해, 명확한 오류가 있는 풀이보다는 설득력있는 오답을 인간 라벨러에게 더 할당해야 한다.
이를 위해, 설득력있는 오답 풀이를 선택한다.
설득력있는 풀이는 현재 최고의 PRM에서 높은 평가를 받은 풀이를 의미하고,
오답 풀이는 잘못된 최종 답에 도달한 풀이를 의미한다.
이러한 설득력있는 오답 풀이과정을 라벨링함으로써 더 많은 정보를 얻을 수 있는데, 적어도 하나의 단계에서 PRM이 실수를 했다는 것을 알 수 있기 때문이다.
2.5 ORM (결과 감독 보상 모델)
기존 ORM의 방법론에 따라 학습시켰다.
ORM은 결과만 확인하기 때문에 잘못된 풀이과정으로 올바른 답에 우연히 도달하는 false positive를 걸러낼 수 없다.
2.6 PRM (과정 감독 보상 모델)
PRM은 각 풀이과정 단계의 마지막 토큰 이후에 해당 단계의 정답률을 예측하도록 훈련한다.
예측한 토큰이 실제 토큰과 얼마나 일치하는지 파악하기 위해 로그우도 (log likelihood)를 최대화한다.

위 그림은 두가지 다른 풀이과정에 대해 PRM점수를 시각화 한 것이다. (좌: 정답, 우: 오답)
초록색으로 칠해진 부분은 높은 PRM점수를 가지나, 빨간색이 될수록 낮은 PRM을 가지게 되고 PRM이 실제로 풀이과정 중 오답인 부분을 찾아내는 것을 확인할 수 있다.
3. Large-scale Supervision (대규모 감독)
PRM의 비교대상인 ORM의 최대 성능을 끌어내기 위해, ORM의 훈련 세트를 PRM800K보다 10배 크게 했다.
또한 기존의 PRM 훈련 방식이 더 설득력있는 오답을 위주로 학습하기 때문에, 답만 보는 ORM은 오답편향의 경향이 있다.
이를 고려하여 더 균일하게 샘플링된 풀이과정을 사용해 ORM의 성능을 높이고자 하였으나, 불가능하였다.
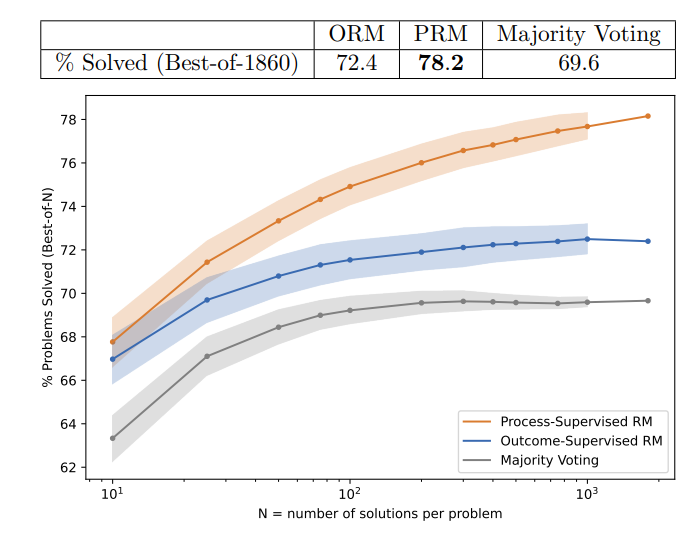
각각의 보상모델이 판단했을 때 고득점을 받은 풀이과정의 정답률, PRM이 ORM보다 높으며, 모두 가장 빈번하게 나온 풀이보다 높은 것을 확인할 수 있다.
4. Small-scale Synthetic Supervision (소규모 합성 감독)
대규모 모델에서는 PRM이 ORM보다 우수하다는 것을 확인했으나,
ORM과 PRM의 훈련 데이터셋이 다르고 PRM의 훈련 데이터는 잘못된 풀이과정에 편향되어 있다는 점,
풀이과정에 상관없이 답만 맞춰 정답 레이블을 받는 경우 ORM의 성능에 영향을 미칠 수 있다는 점으로 인해
PRM과 ORM을 직접적으로 비교할 수 없다.
이러한 요인들로 인해 대형 모델을 직접 비교하려면 인간 피드백 비용이 너무 많이 들게 된다.
이에 소형모델을 직접 비교하고, 라벨링은 대형모델(PRM large)이 하여 인간 피드백을 대신하게 한다.

라벨링한 데이터의 양에 관계없이 PRM + Active Learning이 가장 높은 성능을 보인다.
5. OOD Generalization
out of distribution을 평가하기 위해, 물리학, 미적분학, 화학 등 시험에서 추출한 224개의 STEM 문제에 대해 평가했다.
이 시험 문제들은 훈련데이터셋이 구성된 이후 공개되었기 때문에, 모델이 처음 보는 문제임을 보장할 수 있다.

PRM이 ORM과 voting을 능가하는 것을 확인할 수 있다.
이는 PRM이 일정량의 분포 변화에 견고한것을 보여주며, zero-shot 문제에서도 강력한 성능을 유지한다는 것을 보여준다.
6. Discussion
6.1 Credit Assignment (신용 할당)
과정 감독의 명확한 장점은 결과 감독보다 더 정확한 피드백을 제공한다는 점이다.
결과감독으로 훈련된 보상모델은 어려운 신용할당 문제에 직면하게 되는데, 모델은 오답을 마주했을때 풀이과정의 어느 부분에서 오류가 발생했는지를 스스로 파악해야 하기 때문이다.
특히 어려운 문제, 긴 추론을 요구하는 문제에서 이러한 문제는 두드러진다.
반면 과정감독은 정확한 오류 발생 위치를 모두 명확히 지정해주어, 신용할당을 더 쉽게 만들어주기 때문에 더 강력한 성능을 발휘할 수 있게 된다.
6.2 Alignment Impact (정렬 영향)
과정 감독은 결과 감독보다 정렬과 관련한 장점이 있다.
과정 감독은 인간이 승인한 풀이과정 (인간처럼 풀이) 을 따르도록 유도하기 때문에 해석가능한 추론을 생성할 가능성이 높아진다.
또한 과정감독은 정렬된 사고 과정을 직접적으로 보상하기 때문에 본질적으로 더 안전하다.
6.3 Test Set Contamination (테스트셋 오염)
MATH 데이터셋의 테스트셋은 여러 온라인 사이트에서 이미 논의된 문제를 포함하고 있으며, 이 중 일부는 위에서 훈련한 사전훈련데이터셋에 포함되어 있을 가능성이 있다.
문자열매칭을 통한 휴리스틱을 사용하여 MathMix 데이터셋에서 모든 MATH문제를 제거하려 했으나, 인간이 문제를 온라인에 게시했을 때 감지하기 어려운 정도의 재구성이 있을 수 있기때문에 중복을 완전히 배제하기는 어렵다.
이를 감안하여 풀이과정을 점검해 봤을때, 약간의 미묘한 형태의 암기 가능성을 배제 할 수는 없으며, 테스트셋 오염으로 인해 MATH 테스트셋에서 성능을 약간 상승시켰을 가능성이 있다.
이를 고려하더라도 모든 방법에서 비슷한 방식으로 오염이 발생할것으로 예상되기 때문에, 상대적 비교에는 큰 영향을 미치지 않았을것이다.
'AI' 카테고리의 다른 글
| 모개숲 딥러닝 스터디 - 16. Proximal Policy Optimization Algorithms (0) | 2024.09.29 |
|---|---|
| [논문 리뷰] Time Series Data Augmentation for Deep Learning: A Survey (0) | 2024.09.23 |
| Open AI의 신규 모델, o1 출시 (1) | 2024.09.13 |
| [논문 리뷰] LG EXAONE 3.0 7.8B Instruction Tuned Language Model (1) | 2024.08.17 |
| [SKADA] SK AI Data Academy 1기 중급 수료후기 (0) | 2024.08.11 |