
강화학습이란
인공지능의 학습 방법 중 하나로:
1. 에이전트(Agent)가 환경(Environment)과 상호작용하면서,
2. 최적의 행동 방침(Policy)을 학습한다.
3. 에이전트는 주어진 환경에서 상태(State)를 인식하고, 가능한 행동(Action) 중 하나를 선택한다.
4. 에이전트의 행동 결과로 환경은 보상(Reward)을 주고, 이 보상을 바탕으로 에이전트는 학습을 진행한다.
에이전트(Agent): 환경과 상호작용하며 학습을 진행하는 주체.
환경(Environment): 에이전트가 속한 공간으로, 에이전트의 행동에 따라 상태가 변화하며 보상을 제공.
상태(State): 환경이 에이전트에게 제공하는 정보.
행동(Action): 에이전트가 환경 내에서 선택할 수 있는 행동.
보상(Reward): 에이전트의 행동에 따라 환경이 에이전트에게 주는 피드백.
행동 방침/정책(Policy): 에이전트가 어떤 상태에서 어떤 행동을 선택할지 결정하는 전략.

PPO (Proximal Policy Optimization) Abstract
우리는 강화학습을 위한 새로운 계열의 정책 그래디언트 방법을 제안하며…(중략)…미니배치 업데이트를 여러 차례 수행할 수 있는 새로운 목표 함수를 제안합니다.
우리가 Proximal Policy Optimization(PPO)이라고 부르는 이 새로운 방법은 Trust Region Policy Optimization(TRPO)의 몇 가지 장점을 유지하면서도, 훨씬 더 구현이 간단하고, 더 일반적이며, 샘플 효율성이 더 좋습니다.
PPO의 핵심 아이디어
최대한 큰 step, 그러나 안정적으로
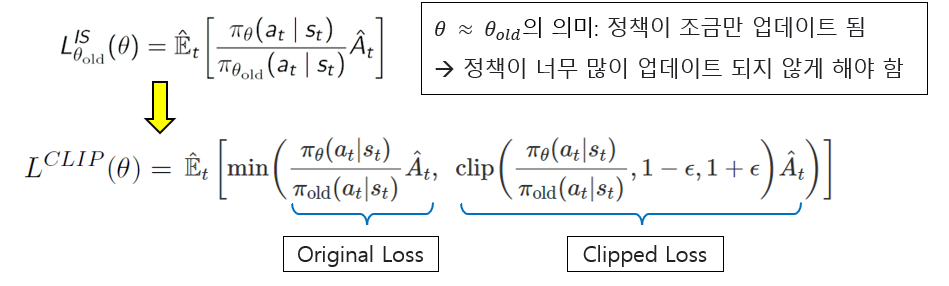
1. 확률 비율 클리핑 (Clipped Probability Ratios)
PPO는 기존 policy와 새로운 policy간의 변화가 너무 크지 않도록 확률비율을 제한
이를 통해 급격한 policy 변화를 방지하고 안정적인 학습을 유지하도록 함
2. 미니 배치 (Mini-batch) 업데이트
기존의 policy gradient 방식은 각 데이터 샘플에 대해 한번의 업데이트만 수행하는 반면,
PPO는 같은 데이터를 여러번 사용해 mini batch 업데이트를 반복
이를 통해 샘플 효율성이 향상되고, 적은 데이터로도 효과적인 학습이 가능
PPO의 구조



Performance
PPO : clipped vs KL penalty

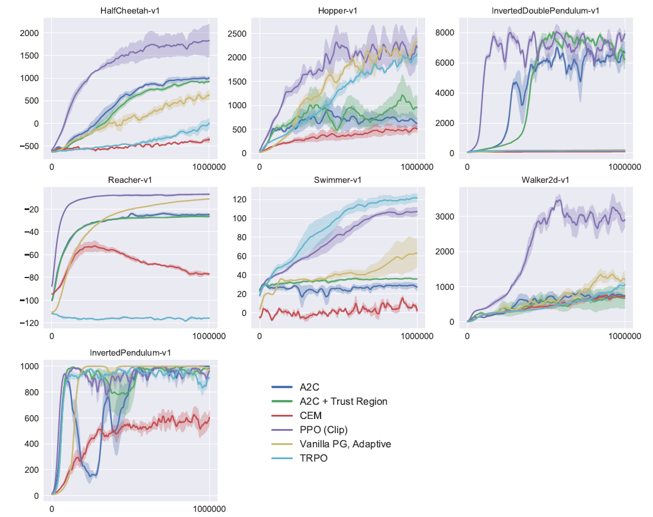
PPO vs Other RL
'AI' 카테고리의 다른 글
| 모개숲 딥러닝 스터디 - 17. End-to-End Autonomous Driving: Challenges and Frontiers (2) | 2024.10.20 |
|---|---|
| [논문 리뷰] Unsupervised Deep Anomaly Detection forMulti-Sensor Time-Series Signals (0) | 2024.10.06 |
| [논문 리뷰] Time Series Data Augmentation for Deep Learning: A Survey (0) | 2024.09.23 |
| [논문 리뷰] Let’s Verify Step by Step (1) | 2024.09.16 |
| Open AI의 신규 모델, o1 출시 (1) | 2024.09.13 |